Chapter 3 Claim Rate & Proportional Rate
3.1 승인률
산업보건에서는 어떠한 질병을 직업병을 인정 받았는지의 율이 있습니다. 이것을 승인률이라고 하는데요, 예를 들어 폐암으로 누군가 산업재해를 신청하는 경우 폐암 유발 물질에 노출될 수 있는 광업 등에서는 승인률이 높을 것이고, 그렇지 않은 업종에서는 승인률이 낮을 것으로 생각이 됩니다. 이를 분석하는 과정을 통해 이야기 해보고자 합니다.
DsPub 데이터 베이스에서 산재 신청자료와 인정 자료를 불러오겠습니다.
s_cancer1 = dbGetQuery(con, "select * from sanjae.cancer")
claim1 = dbGetQuery(con, "select * from sanjae.claim")3.1.1 데이터 표준화
본 분석에서는 아래와 같이 데이터를 표준화 하였습니다. 표준화 방법에 따라 결과가 바뀔 수 있어 코드를 나열합니다.
claim2 = claim1 %>% tibble() %>%
select(연도구분, 성별, 출생연도, 사업장규모, 업종코드, 업종명, 직종코드, 직종명, `직업병명(대)`, 승인구분, 상병명, 접수일자, 결재일자 ) %>%
mutate(`업종병2` = str_replace_all(업종명, " ", "")) %>%
setNames(c("year", "gender", "birthyear", "factorysize",
"indcode", "indname", "jobcode","jobname", "dz1", "approval", "dz2", "sttime", "edtime", "indname2")) %>%
mutate(sttime = ymd(sttime), edtime = ymd(edtime)) %>%
mutate(diff_in_days = difftime(edtime, sttime, units = "days") %>% as.numeric()) %>%
mutate(factorysize = factor(factorysize,
levels=c('5~30인 미만',
'30~50인 미만',
'50~100인 미만',
'100~300인 미만',
'300~500인 미만',
'500~1000인 미만',
'1000인 이상'
)))
claim3<-claim2 %>%
mutate(ind4d = substr(indcode, 1, 4)) %>%
mutate(ind3d = substr(indcode, 1, 3)) %>%
mutate(ind2d = substr(indcode, 1, 2)) %>%
mutate(ind1d = substr(indcode, 1, 1)) %>%
mutate(ind1_source =factor(ind1d,
#levels =c(),
labels =c(
'금융업',
'광업',
'제조업',
'가스수도전기',
'건설업',
'운수통신창고',
'농림어업',
'농림어업',
'농림어업',
'사회서비스'
))) %>%
mutate(ind2_source =case_when(
ind3d %in% c('000') ~ '금융업',
ind2d %in% c('10') ~ '광업등',
ind4d %in% c('2000', '2001') ~ '식품제조업',
ind4d %in% c('2020', '2320') ~ '섬유제조업',
ind4d %in% c('2030','2040', '2050', '2041') ~ '목재종이제조',
ind4d %in% c('2060', '2070') ~ '인쇄업',
ind4d %in% c('2090') ~ '도료화학제조',
ind4d %in% c('2091', '2120') ~ '고무플라스틱제혁',
ind4d %in% c('2100') ~ '의약화장품',
ind4d %in% c('2110', '2380') ~ '코크스석탄가스',
ind4d %in% c('2130', '2140', '2141', '2150', '2160') ~ '유리도자기시멘트제조',
ind4d %in% c('2180') ~ '건설관련 금속비금속제조',
ind4d %in% c('2181', '2190', '2200','2210' ) ~ '금속제조(용접압연합금)',
ind4d %in% c('2182', '2183', '2230', '2231') ~ '금속기계제조',
#ind4d %in% c('2184') ~ '자동차제조',
ind4d %in% c('2220') ~ '도금업',
ind4d %in% c('2240','2241', '2250') ~ '전기통신기계제조',
ind4d %in% c('2260') ~ '강선건조수리',
ind4d %in% c('2184', '2270', '2340', '2350') ~ '운송기기/부품수리제조',
ind4d %in% c('2280') ~ '정밀광학의료기계제조',
ind4d %in% c('2290', '2291', '2300') ~ '기타제조업',
ind4d %in% c('2380') ~ '연탄 생산',
ind4d %in% c('3000') ~ '가스수도전기업',
ind4d %in% c('4000', '4001', '4003', '4030') ~ '건설공사',
ind2d %in% c('50', '50') ~ '운수창고업',
ind4d %in% c('5100') ~ '신문통신',
ind4d %in% c('5110') ~'운수창고업',
ind2d %in% c('60', '70', '80') ~'농림어업',
ind4d %in% c('9010') ~'건물관리',
ind4d %in% c('9020') ~'하수도업',
indname %in% c('90501') ~'음식숙박서비스',
indname %in% c('90502') ~'사업서비스',
indname %in% c('90504') ~'개인및가사서비스',
indname %in% c('90701', '90703', '90702') ~'정보연구법무서비스',
ind4d %in% c('9080', '9090') ~'보건사회복지교육서비스',
ind2d %in% c('91', '99') ~'임대및관리서비스',
TRUE ~ '기타'
)) %>%
mutate(job1code = substr(jobcode, 1, 1)) %>%
mutate(job1_source =factor(job1code,
#levels =c(),
labels =c(
'관리자',
'전문가',
'사무',
'서비스',
'판매',
'농림어업',
'기능원및관련',
'장치기계조작및조립',
'단순노무',
'특수',
'특수'
)))3.1.2 최근 5년 산재 신청 건수 및 승인률
3.1.3 암 승인률
cancer = claim3 %>%
filter(dz1 =='악성신생물(직업성 암 포함)')tb1 = make.table(dat = cancer,
strat = c("approval"),
cat.varlist=c("gender", "ind1_source", "job1_source", "factorysize"),
cat.rmstat = list(c("count", "col", "miss")),
cat.ptype = c("chisq"),
cont.varlist=c('diff_in_days'),
cont.rmstat = list(c("count","miss", "minmax", "q1q3", "mediqr")),
cont.ptype = c( "ttest")
) rownames(tb1) <- c()
tb1 %>% htmlTable()| Variable | 불승인 | 승인 | Overall | p.value | |
|---|---|---|---|---|---|
| 1 | gender | <0.001 | |||
| 2 | (Row %) | Chi-square | |||
| 3 | 남 | 1362 (29.81%) | 3207 (70.19%) | 4569 (100.00%) | |
| 4 | 여 | 396 (62.26%) | 240 (37.74%) | 636 (100.00%) | |
| 5 | |||||
| 6 | factorysize | <0.001 | |||
| 7 | (Row %) | Chi-square | |||
| 8 | 5~30인 미만 | 414 (36.13%) | 732 (63.87%) | 1146 (100.00%) | |
| 9 | 30~50인 미만 | 126 (38.18%) | 204 (61.82%) | 330 (100.00%) | |
| 10 | 50~100인 미만 | 177 (39.86%) | 267 (60.14%) | 444 (100.00%) | |
| 11 | 100~300인 미만 | 234 (36.28%) | 411 (63.72%) | 645 (100.00%) | |
| 12 | 300~500인 미만 | 78 (24.53%) | 240 (75.47%) | 318 (100.00%) | |
| 13 | 500~1000인 미만 | 102 (18.38%) | 453 (81.62%) | 555 (100.00%) | |
| 14 | 1000인 이상 | 393 (34.29%) | 753 (65.71%) | 1146 (100.00%) | |
| 15 | |||||
| 16 | diff_in_days | 0.015 | |||
| 17 | Mean (SD) | 334.26 (258.92) | 352.26 (238.20) | 346.18 (245.51) | t-test |
| 18 | |||||
| 19 | ind1_source | <0.001 | |||
| 20 | (Row %) | Chi-square | |||
| 21 | 금융업 | 51 (62.96%) | 30 (37.04%) | 81 (100.00%) | |
| 22 | 광업 | 120 (10.18%) | 1059 (89.82%) | 1179 (100.00%) | |
| 23 | 제조업 | 804 (34.54%) | 1524 (65.46%) | 2328 (100.00%) | |
| 24 | 가스수도전기 | 18 (75.00%) | 6 (25.00%) | 24 (100.00%) | |
| 25 | 건설업 | 90 (17.65%) | 420 (82.35%) | 510 (100.00%) | |
| 26 | 운수통신창고 | 114 (55.88%) | 90 (44.12%) | 204 (100.00%) | |
| 27 | 농림어업 | 9 (75.00%) | 3 (25.00%) | 12 (100.00%) | |
| 28 | 사회서비스 | 537 (63.03%) | 315 (36.97%) | 852 (100.00%) | |
| 29 | |||||
| 30 | job1_source | <0.001 | |||
| 31 | (Row %) | Chi-square | |||
| 32 | 관리자 | 252 ( 71.79%) | 99 ( 28.21%) | 351 (100.00%) | |
| 33 | 전문가 | 126 ( 53.85%) | 108 ( 46.15%) | 234 (100.00%) | |
| 34 | 사무 | 123 ( 95.35%) | 6 ( 4.65%) | 129 (100.00%) | |
| 35 | 서비스 | 36 ( 63.16%) | 21 ( 36.84%) | 57 (100.00%) | |
| 36 | 판매 | 27 (100.00%) | 0 ( 0.00%) | 27 (100.00%) | |
| 37 | 농림어업 | 6 ( 40.00%) | 9 ( 60.00%) | 15 (100.00%) | |
| 38 | 기능원및관련 | 219 ( 20.62%) | 843 ( 79.38%) | 1062 (100.00%) | |
| 39 | 장치기계조작및조립 | 309 ( 34.68%) | 582 ( 65.32%) | 891 (100.00%) | |
| 40 | 단순노무 | 657 ( 27.00%) | 1776 ( 73.00%) | 2433 (100.00%) | |
| 41 | 특수 | 3 ( 50.00%) | 3 ( 50.00%) | 6 (100.00%) | |
| 42 |
#tb1 %>% datatable(options = list(pageLength = 50, extensions = 'Buttons'))3.1.4 암종별 승인률
3.1.4.1 암 질병명 표준화
우선 산재 자료는 질병을 표준화할 필요가 있음.
cancer2 = cancer %>%
mutate(dz3 = case_when(
str_detect(dz2, "폐암|폐|폐선암|기관지|악성폐|비소세포|폐 악성신|하엽폐|하엽 편평상피암|소세포|lung|Lung|패암|퍠임|페암4기|퍠암") ~ '폐암',
str_detect(dz2, "백혈병|림프종|골수형성이상증후군|골수|빈혈|림프|leu|lympho|AML") ~ '혈액암',
str_detect(dz2, "악성 중피종|흉막|중피종|악성중피중|종피종|mesothelioma") ~ '악성중피종',
str_detect(dz2, "간세포암|간암|담도|담관|간의|간세포성") ~ '간담도암',
str_detect(dz2, "위암|위의|위 악성") ~ '위암',
str_detect(dz2, "뇌|교모세포종|성상|아교") ~ '뇌암',
str_detect(dz2, "유방|분문|breast|Breast") ~ '유방암',
str_detect(dz2, "갑상선") ~ '갑상선암',
str_detect(dz2, "신장|신우|kidney") ~ '신장암',
str_detect(dz2, "방광|요관") ~ '방광요관암',
str_detect(dz2, "대장|결장|직장|colon|Colon") ~ '대장암',
str_detect(dz2, "비인두|부비동|구강|상악동|비강|비인강|구인두|후두|두경부|설암|상악|성문") ~ '구강비강후두암',
str_detect(dz2, "식도") ~ '식도암',
str_detect(dz2, "흑색종|피부") ~ '피부암',
str_detect(dz2, "육종|근섬유") ~ '육종암_근암',
str_detect(dz2, "난소") ~ '난소암',
str_detect(dz2, "췌장") ~ '췌장암',
str_detect(dz2, "갑상") ~ '갑상선암',
TRUE ~ '기타' #dz2
)) 3.1.4.2 암 종류별 승인율
cancer2 %>%
group_by(dz3) %>%
count(approval) %>%
mutate(claim_number = sum(n),
approval_rate= round(n/sum(n), 2)) %>%
filter(approval == '승인') %>%
select(-approval, -n) %>%
arrange(desc(approval_rate)) %>%
datatable(options=list(pageLength = 15))3.1.4.3 업종별 암별 승인율
먼저 업종 표준화에 수작업이 상당부분 이루어져야 의미를 갖을 수 있으며, 해석에 주의를 요함. 예를 들어 아래의 그림은 폐암 승인된 사례고,이때 금융업이 이에 포함됨.

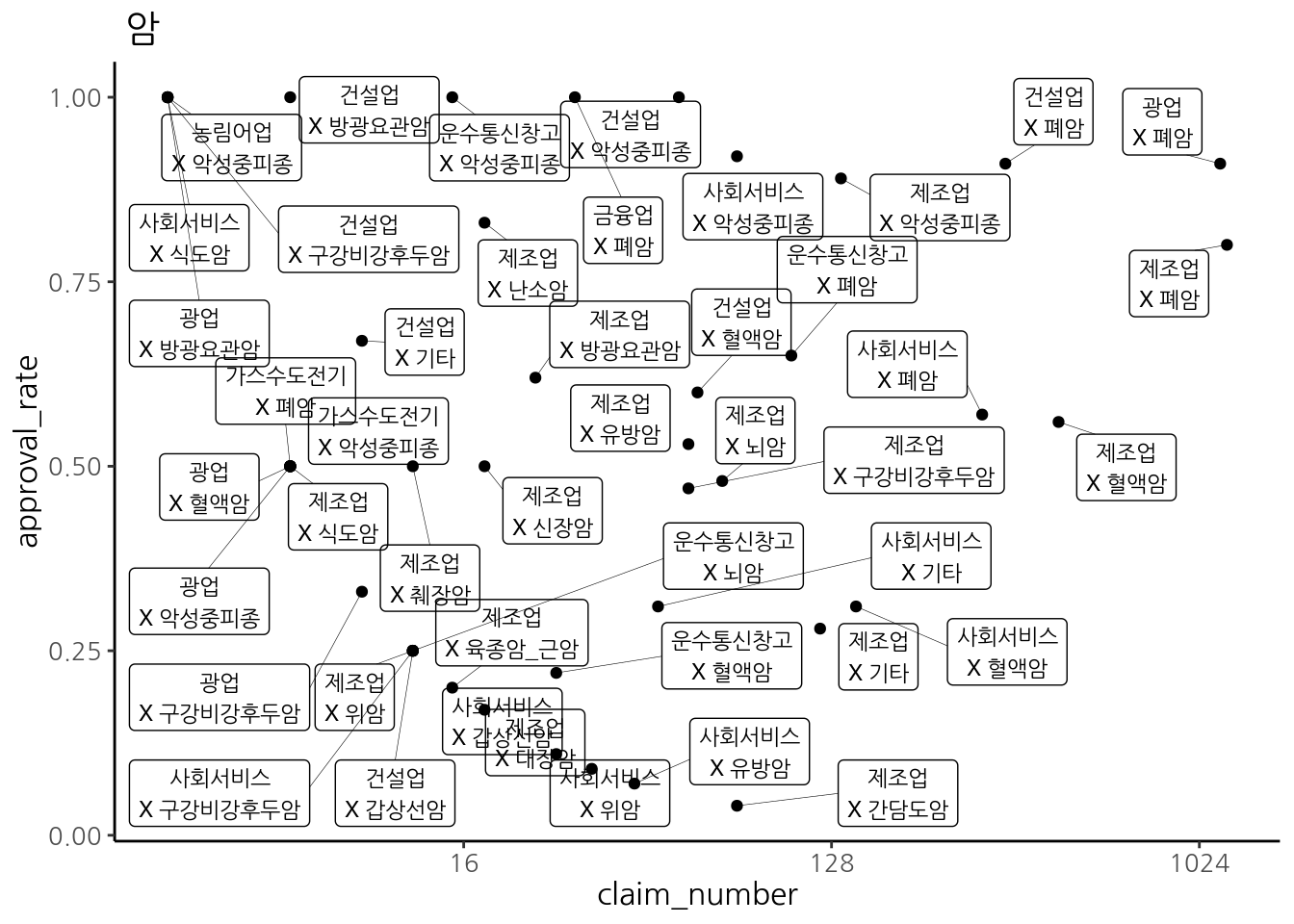
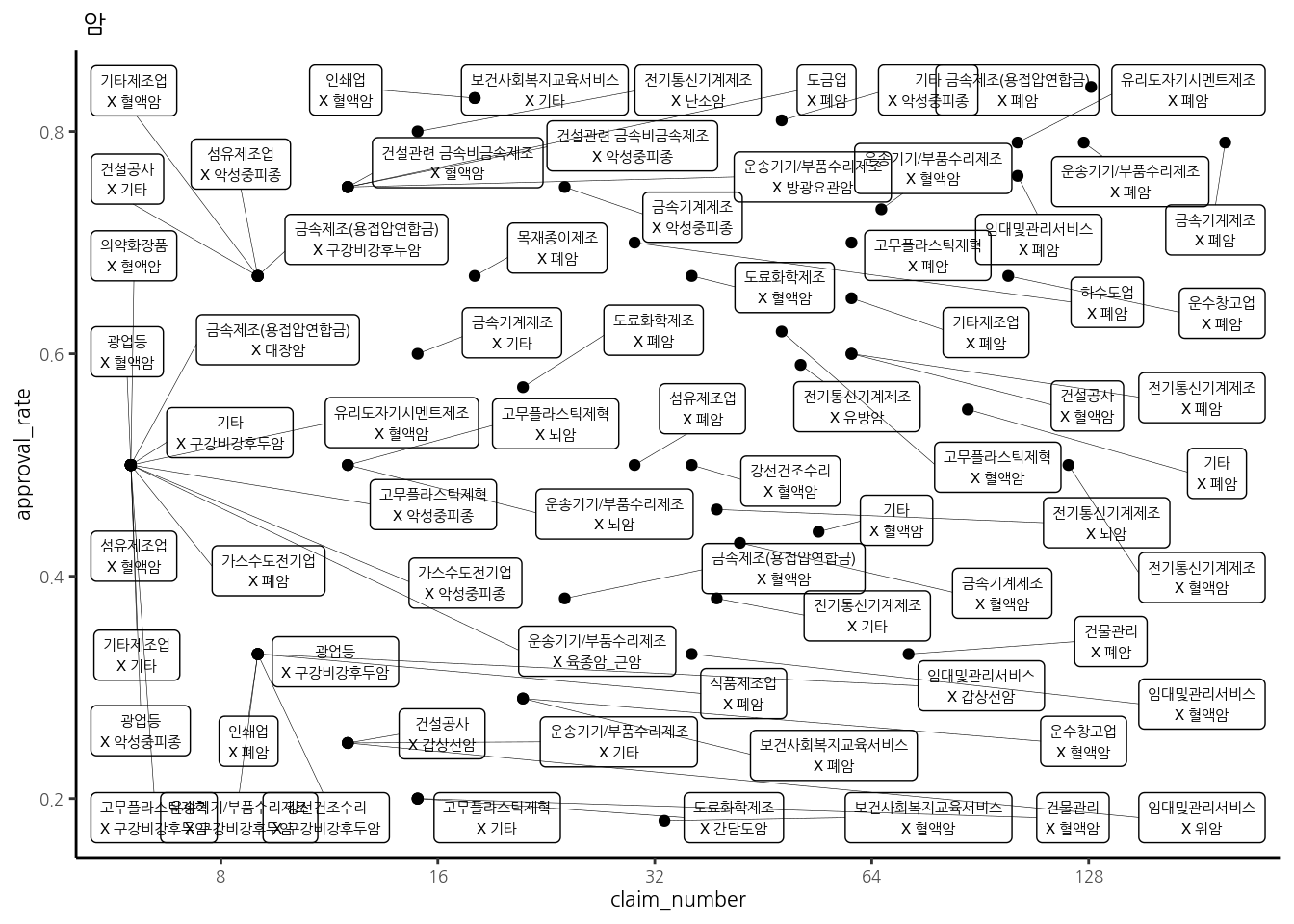
3.1.4.4 중분류 업종별 암 승인율
승인률 90% 이상인 중분류와 암 종류
승인률 90% 인 중분류와 암 종류의 분포
3.2 신청률
3.2.1 데이터 불러오기
데이터 불러오기
dat1 <- read_xlsx('data/claim/indaccident.xlsx')
pops <- read_xlsx('data/claim/pops.xlsx')3.2.2 질병 표준화
질병 표준화 lookup 파일 생성
copd_source <- c('만성폐쇄성페질환', 'copd', '만성폐쇄성폐질환',
'만성폐쇄성폐질환(copd)', '폐기종','만성폐쇄성질환',
'만성폐색성폐질환', '상세불명의만성폐쇄성폐질환',
'상세불명의만성폐색성폐질환')
copd_source2 <-c('폐색성폐질환|만석폐색성폐질환|만성폐쇄성폐|만성폐색성폐|폐쇄성폐질환|만성퍠쇄성폐|만성폐쇄성|copd|만성폐색성|만성폐쇅성|만성패쇄성|만성페쇄성폐질환')
lungca_source <- c("폐암|폐의악성|lungcancer|lugcancer|페암|폐선암|폐상엽의악성신생물|소세포암|폐종양|폐문의악성신생물|기관지악성|폐상피세포암|폐악성종양|편평상피세포암|폐의선암종|폐의편평상피|폐편평세포|기관지의악성|malignantneoplasmoflowerlobe|기관지또는폐의왼쪽의악성신생물")
brainca_source <-c("뇌암|뇌종양|뇌간신경교종|성상세포종|교모세포종|뇌의악성")
liverca_source <- c('간암|간세포암|livercancer|담관암|간세포성암종|간의혈광육종|담도암|담관의악성')
hepatitis_source <-c('hepatitis')
mms_source <-c('악성중피|중피종|malignantmeso|흉막의악성|흉막중피종|복막중피종')
oralca_source <-c('구강암|후두암|비강암|비인강암|상악동암|비인두암|두경부암|편도암|부비동의악성|비인두의악성|성문암')
gastricca_source <-c('위암|식도암|식도의악성|위악성신생물')
asbesto_source <-c('석면폐|흉막판|흉막반|asbestosis|ashesto')
breastca_source <-c('유방암|breastcancer|유방상피내암|유방의악성|유방의중앙부')
pnuemonia_source <-c('폐렴|기관지염|기관지확장증|pnumonia|pneumonia')
heat_source <-c("탈수|열사|일사|열탈|heatstro|탈수|열경련|열손상|열실신|열졸증|열피로")
leukemia_source <-c("백혈병|림프종|골수이형성|다발성골수종|혈액암")
thyroidca_source <-c("갑상선의악성신생물|갑상선암|갑상샘의유두암종|갑상선의유두")
mmsclerosis_source<-c("다발성경화증")
dementia_source <-c("치매|dementia")
asthma_source <-c("천식|asthma")
gica_source <-c('직장암|췌장암|췌장의악성|결장의악성|결장암|대장암|직장유암|coloncancer')
als_source <-c('근위축성축상경화증|als|전신성경화증')
bladderca_source <-c('방광암|방광삼각부의악성신생물|방광의악성')
kidneyca_source <-c('신장암|신세포암')
skinca_source <-c('흑색종|피부혈관육종')
cold_source <-c('동상')
ovary_source <-c('난소암|난소의악성')
kidney_dz_source <-c('신질환|신부전|콩팥손상')
unkown <- c()질병 표준화 변환 파일 생성
ds1<-dat1 %>%
#select(-num, -year, -ind_code, -ind_source, -job_code, -job_source) %>%
mutate(dzc2 = str_replace_all(dzc2, " ", "")) %>%
mutate(dzc2 = tolower(dzc2)) %>%
mutate(ds = case_when(
## 중분류에서 가져오기
dzc %in% c('진동으로 인한 증상') ~'진동으로 인한 증상',
#dzc %in% c('정신질환, 자해행위') ~'정신질환',
#dzc %in% c('자해행위(자살 포함)') ~'자살',
dzc %in% c('독성감염') ~'감염질환',
dzc %in% c('기타 간질환') ~'기타 간질환',
dzc %in% c('안질환') ~'안질환',
dzc %in% c('피부질환') ~'피부질환',
dzc %in% c('사인미상') ~'사인미상',
dzc %in% c('심장질환', '뇌혈관질환') ~'뇌심혈관질환',
#dzc %in% c('일사병,열사병,화상,동상') ~'기타 이상기온',
str_detect(dzc, '정신질환') ~'정신질환',
#str_detect(dzc2, '자살') ~'자살',
str_detect(dzc, '이상기압') ~'이상기압',
## 세분류 변형
dzc2 %in% copd_source ~'만성폐쇄성폐질환',
str_detect(dzc2, copd_source2) ~'만성폐쇄성폐질환',
str_detect(dzc2, lungca_source) ~'폐암',
str_detect(dzc2, c('기관기및폐의중복병변')) ~'폐암',
str_detect(dzc2, breastca_source) ~'유방암',
str_detect(dzc2, pnuemonia_source) ~'폐렴',
str_detect(dzc2, '진폐|규폐|진페') ~'진폐',
str_detect(dzc2, leukemia_source) ~'백혈병',
str_detect(dzc2, '쯔쯔가무') ~'쯔쯔가무시병',
str_detect(dzc2, '특발성폐섬유') ~'특발성폐섬유',
str_detect(dzc2, '결핵|tuber') ~'결핵',
str_detect(dzc2, mms_source) ~'악성중피종',
str_detect(dzc2, '안면마비|벨마비|facialpalsy|bell') ~'안면마비',
str_detect(dzc2, '중증열성혈소판감소증후군') ~'중증열성혈소판감소증후군',
str_detect(dzc2, liverca_source) ~'간세포암',
str_detect(dzc2, oralca_source) ~'구강암',
str_detect(dzc2, gastricca_source) ~'위식도암',
str_detect(dzc2, heat_source) ~'온열질환',
str_detect(dzc2, thyroidca_source) ~'갑상선암',
str_detect(dzc2, brainca_source) ~'뇌암',
str_detect(dzc2, asbesto_source) ~'석면폐증/흉막반',
str_detect(dzc2, dementia_source) ~'치매',
str_detect(dzc2, asthma_source) ~'천식',
str_detect(dzc2, gica_source) ~'기타 소화기암',
str_detect(dzc2, bladderca_source) ~'방광암',
str_detect(dzc2, kidneyca_source) ~'신장암',
str_detect(dzc2, als_source) ~'전신경화증',
str_detect(dzc2, skinca_source) ~'피부암',
str_detect(dzc2, cold_source) ~'동상',
str_detect(dzc2, ovary_source) ~'난소암',
str_detect(dzc2, kidney_dz_source) ~'신장암',
str_detect(dzc2, '간질성폐질환') ~'간질성폐질환',
TRUE ~ '기타'
)) %>%
mutate(ds2 = case_when(
str_detect(dzc, "자해") & str_detect(dzc2, "자살|목맴|의사|질식|추락|투신") ~ '자살',
str_detect(dzc, "자살") ~ '자살',
TRUE ~ ds
))3.2.3 업종 표준화
업종 표준화는 산재율 발표 자료(kosis.co.kr)의 대분류와 중분류를 이용함. 이때 2018년 상기 근로자수를 모수로 이용함.
ds2 <- pops %>% select(ind2, popu, inds, ind_code) %>%
full_join(ds1, by = c('ind_code')) %>%
select(inds, ind_code, ind2, popu, ds2)
ds2 %>%
select('main'=inds, 'industry'=ind2, 'codes'=ind_code, popu)%>%
datatable()3.2.4 질병/업종 점수화 (10점 만점)
질병/업종을 점수화 하기 위해 로그화 하고 최대 점을 10점 최저 점을 0.1로 표준 점수화 수행, 이후 데이터 병합
ind_sc <-ds2 %>%filter(!is.na(ind2)) %>%
group_by(ind2) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
mutate(sums = sum(n),
min = min(n),
max = max(n),
prob = n/sums*100,
sc_ind =(log(n)-log(min)+1)/(log(max)-log(min)+1))
dz_sc <-ds2 %>%
group_by(ds2) %>%
count() %>%
arrange(desc(n)) %>%
#filter(n > 3) %>%
ungroup() %>%
mutate(n_dz =n,
sums_dz = sum(n),
min_dz = min(n),
max_dz = max(n),
prob_dz = n/sums_dz*100,
sc_dz =(log(n)-log(min_dz)+1)/(log(max_dz)-log(min_dz)+1))
ds3 <- ds2 %>%
full_join(dz_sc %>% select(ds2, sc_dz), by = c('ds2')) %>%
full_join(ind_sc %>% select(ind2, sc_ind), by = c('ind2'))3.2.5 신청률비 (claim rate ratio)
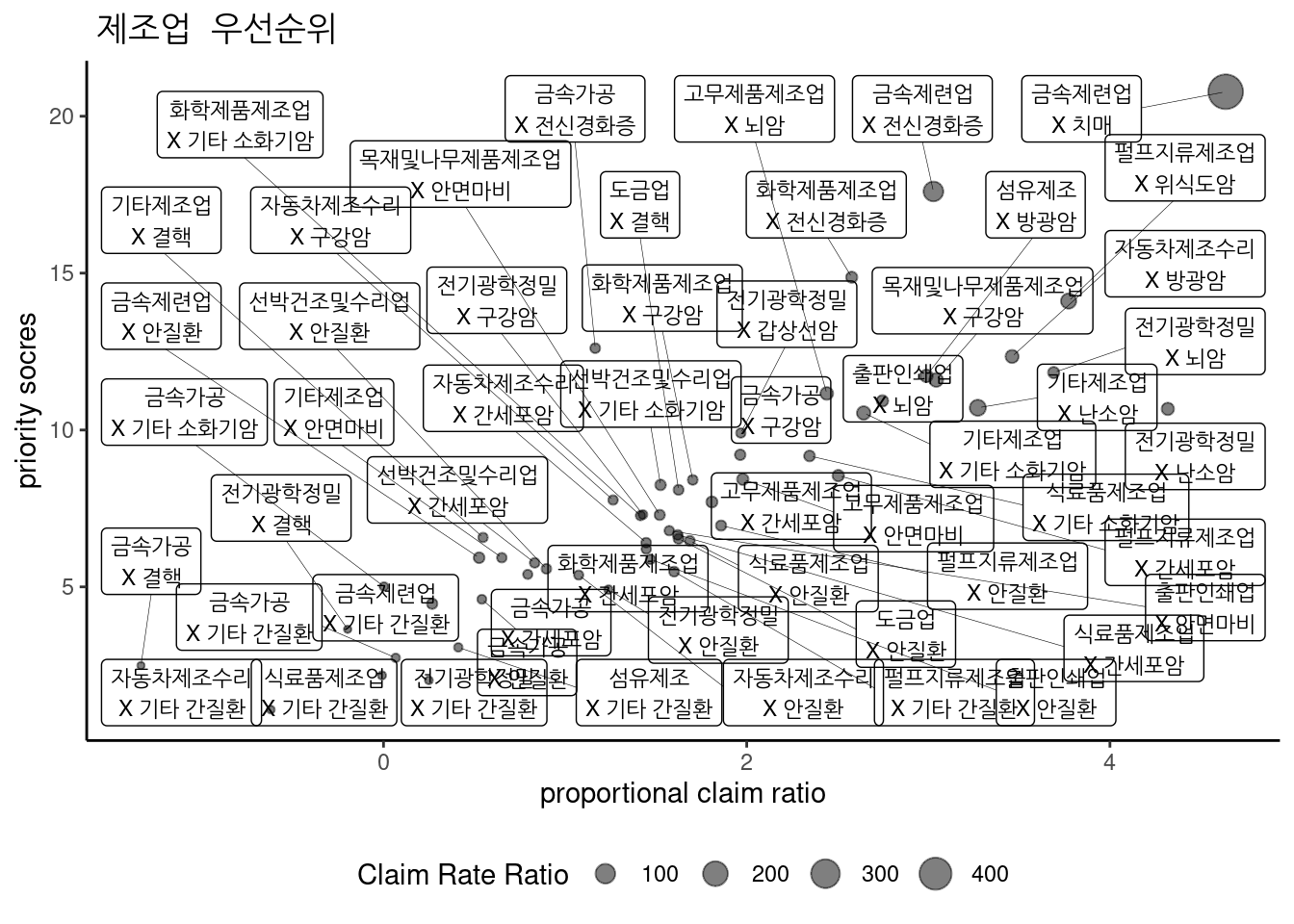
2018 kosis 산업재해 통계자료에 업종 중분류에 따른 근로자수를 이용하여, 총 근로자 수 중에 특정 질병 신청률과 특정 업종의 특정 질병 신청률의 비를 구함. 산재 업종 중분류에 따른 근로자수를 나타내면 아래와 같다.
# 전체 근로자수
tpopu <- pops %>%
pull(popu) %>%
unique() %>% sum(., na.rm = TRUE)
tpopu## [1] 21122868총 근로자 수는인 tpopu 는 2.1122868^{7}이다. 산재 업종 전체 근로자에서 특정 질병 신청률은 다음과 같다.
#정체 업종별
claim_rate_total <- ds2 %>%
group_by(ds2) %>%
count() %>%
mutate(tpopu = tpopu) %>%
rename(dz_count_in_total = n) %>%
mutate(claim_rate_total = dz_count_in_total/tpopu *10^6 ) %>%
#10만 근로자 당 신청률
mutate(claim_rate_total = round(claim_rate_total, 2)) %>%
arrange(desc(dz_count_in_total))
datatable(claim_rate_total)## claim ratio ratio
crr <- ds2 %>%
select(ind2, ds2, popu) %>%
group_by(ind2,popu) %>%
count(ds2) %>%
mutate(claim_rate_ind = n/popu) %>%
rename(dz_count_ind = n) %>%
left_join(claim_rate_total , by = c('ds2') ) %>%
mutate(claim_rate_ratio = claim_rate_ind/claim_rate_total*10^6) %>%
mutate(crr = claim_rate_ratio) %>%
ungroup()3.2.6 비례신청비 (Proportional claim ratio)
질병과 업종의 조합 별 특이성을 반영하기 위해 비례신청비를 산출. 비례신청비는 전체 업종에서의 특정 질병 신청에 비해, 특정 업종에서의 특정 질병 신청이 높을 경우 1점 초과 점수를 아닐 경우 1점 미만 점수를 주는 방식임. 이때 강도를 조정하기 위해 비율을 하용하여 만약 2점인 경우 전체 집단의 특정 질병 신청에 비해 상기 집단에서의 질병 신청은 2배라는 의미임. 다만, 우선 순위 설정으로 p value는 산출하지 않음.
## proportional claim rate
pcr1 <- ds2 %>%
select(ind2, ds2) %>%
group_by(ind2) %>%
count(ds2) %>%
mutate(dz_count_in_ind = n,
total_count_in_ind = sum(n) ) %>%
select(-n) %>%
ungroup() %>%
left_join(ds3 %>% count(ds2), by ='ds2') %>%
rename(dz_count_in_total = n) %>%
mutate(total_count_in_total = sum(dz_count_in_ind)) %>%
mutate(pcr = (dz_count_in_ind/total_count_in_ind)/
((dz_count_in_total - dz_count_in_ind+1)/(total_count_in_total - total_count_in_ind))) 3.2.7 통합 데이터 산출
상기 점수를 모두 합친 데이터를 산출 및 업종 X 질병 조합 변수 표식화.
ds3.1 <-ds3 %>% ungroup() %>%
full_join(pcr1%>% select(ds2, ind2, pcr, dz_count_in_ind) , by = c('ds2', 'ind2')) %>%
full_join(crr %>% select(ds2, ind2, crr), by = c('ds2', 'ind2') )
ds4<-ds3.1 %>%
select(inds, ind2, ds2, dz_count_in_ind, sc_dz, sc_ind, crr, pcr) %>%
unique() %>%
select('ind_main' = inds,
'industry' = ind2,
'disease' = ds2,
'count' = dz_count_in_ind,
sc_ind, sc_dz, crr, pcr) %>%
mutate(sc_ind_dz = sc_ind * sc_dz*100,
sc_ind_dz_pcr = sc_ind_dz * pcr,
sc_ind_dz_sum = sc_ind + sc_dz) %>%
arrange(desc(sc_ind_dz))
ds5 <- ds4 %>%
mutate(names = paste(industry, paste0('X ',disease), sep = "\n"))
openxlsx::write.xlsx(ds5,'data/claim/ds5.xlsx', overwrite = TRUE)대분류 업종 데이터 산출 및 오버뷰
ds5 %>%
group_by(ind_main, industry) %>%
count() %>%
datatable()모든 항목 중분류를 이용함.
3.2.8 데이터 저장
다만 그림을 그리기 위해 업종 이름을 아래와 같이 요약 함. 중 분류는 유지됨.
ds6 <- ds5 %>%
mutate(industry =case_when(
industry == "코크스연탄및석유정제품제조업" ~ "석유정제업",
industry == "출판인쇄제본또는인쇄물가공업" ~ "출판인쇄업",
industry == "철도궤도삭도항공운수업" ~ "철도항공",
industry == "전기기계기구전자제품계량기광학기계기타정밀기구제조업" ~ "전기광학정밀",
industry == "전기가스증기및수도사업" ~ "전기가스수도",
industry == "의약품화장품향료담배제조업" ~ "의약화장품",
industry == "위생및유사서비스업" ~ "위생업",
industry == "운수관련서비스업" ~ "운수서비스",
industry == "오락문화및운동관련사업" ~ "오락운동",
industry == "어업양식어업및어업관련서비스업" ~ "어업",
industry == "자동차운수업및택배업퀵서비스업" ~ "운수택배",
industry == "수송용기계기구제조업자동차및모터사이클수리업" ~ "자동차제조수리",
industry == "수상운수업항만하역및화물취급사업" ~ "수상운수하역",
industry == "섬유또는섬유제품제조업" ~ "섬유제조",
industry == "석회석금속비금속광업및기타광업" ~ "비금속광업",
industry == "도소매및소비자용품수리업업" ~ "용품수리업",
industry == "기계기구비금속광물제품금속제품제조업또는금속가공업" ~ "금속가공",
industry == "도자기기타요업제품시멘트제조업" ~ "도자기시멘트",
TRUE ~ industry
)) %>%
mutate(names = paste(industry, paste0('X ',disease), sep = "\n"))
openxlsx::write.xlsx(ds6, 'data/claim/ds6.xlsx', overwrite = TRUE)3.2.9 업종 점수
업종 점수 표는 아래와 같다.
ds5 <- readxl::read_xlsx('data/ds6.xlsx')
ds5 %>%
select(industry, sc_ind) %>%
unique() %>%
arrange(desc(sc_ind) ) %>%
datatable()업종 그림은 아래와 같다.
ds5 %>%
#filter(count >3) %>%
select(industry, sc_ind) %>%
unique() %>%
arrange((sc_ind) ) %>%
mutate(priority = row_number()) %>%
ggplot(aes(priority, sc_ind)) +
geom_point()+
geom_text_repel(aes(label = industry), size = 2.5) +
geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() + ylim(-0.1, 1)+
ylab("industry score") 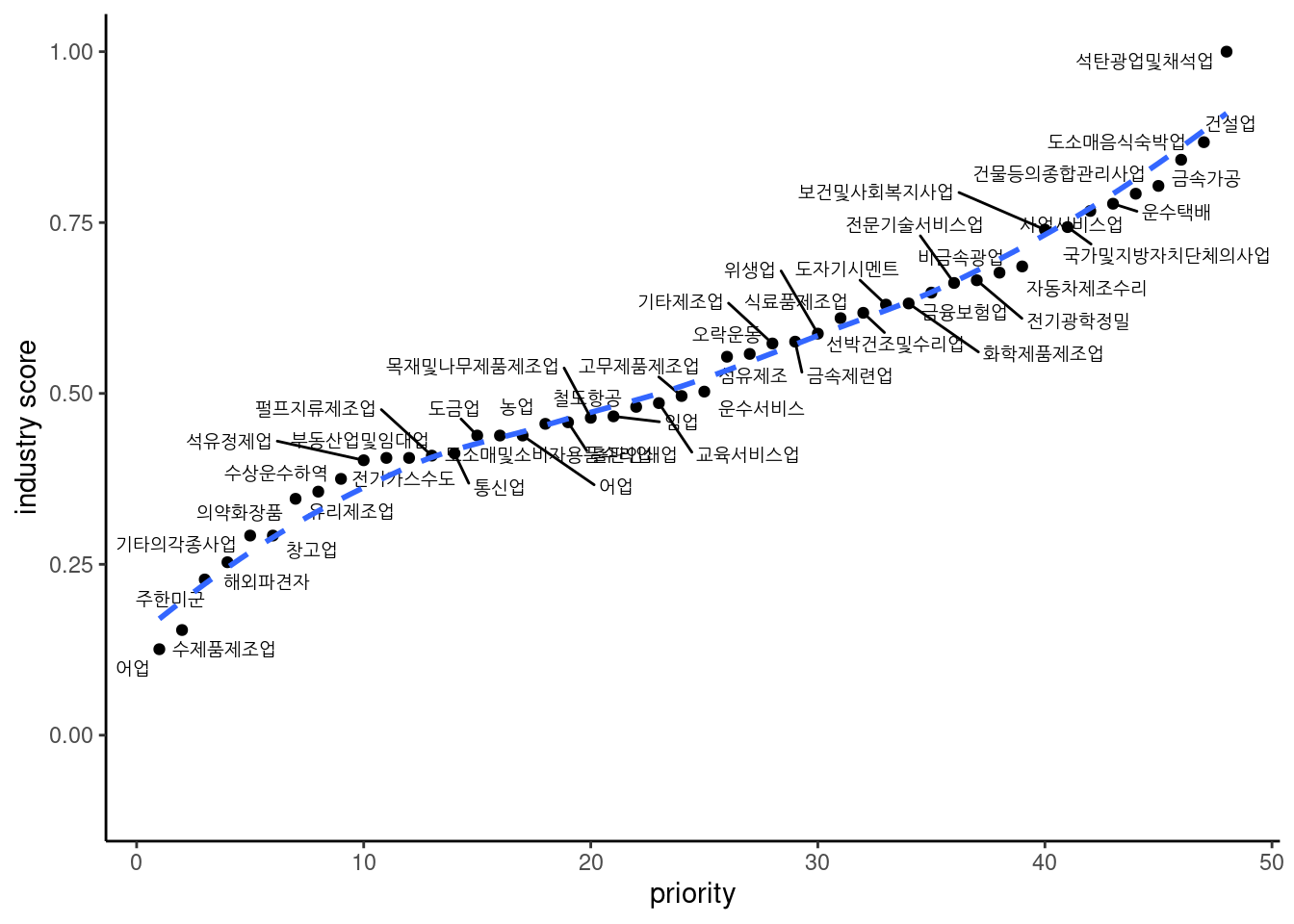
3.2.10 질병 점수
질병 점수 표 및 그림은 아래와 같다.
ds5 %>%
select(disease, sc_dz) %>%
mutate(sc_dz = round(sc_dz, 2)) %>%
unique() %>%
arrange(desc(sc_dz) ) %>%
datatable()ds5 %>%
select(disease, sc_dz) %>%
unique() %>%
arrange((sc_dz) ) %>%
mutate(priority = row_number()) %>%
ggplot(aes(priority, sc_dz)) +
geom_point()+
geom_text_repel(aes(label = disease)) +
geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("disease score")
3.2.11 업종 X 질병 조합 점수
표 및 그래프는 다음과 같음 (그림은 상위 50개)
ds5 %>%
select(names, sc_ind_dz) %>%
mutate(sc_ind_dz = round(sc_ind_dz, 2)) %>%
arrange(desc(sc_ind_dz)) %>%
datatable()ds5 %>%
select(names, sc_ind_dz) %>%
mutate(sc_ind_dz = round(sc_ind_dz, 2)) %>%
arrange(sc_ind_dz) %>%
mutate(priority = row_number()) %>%
slice(656:686) %>%
ggplot(aes(priority, sc_ind_dz)) +
geom_point()+
#geom_text(aes(label = names))+
geom_label_repel(aes(label = names), fill = NA,
alpha =0.8, size = 2) +
geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() + ylim(40, 110) + #xlim(450, 550)+
ylab("disease * industry score")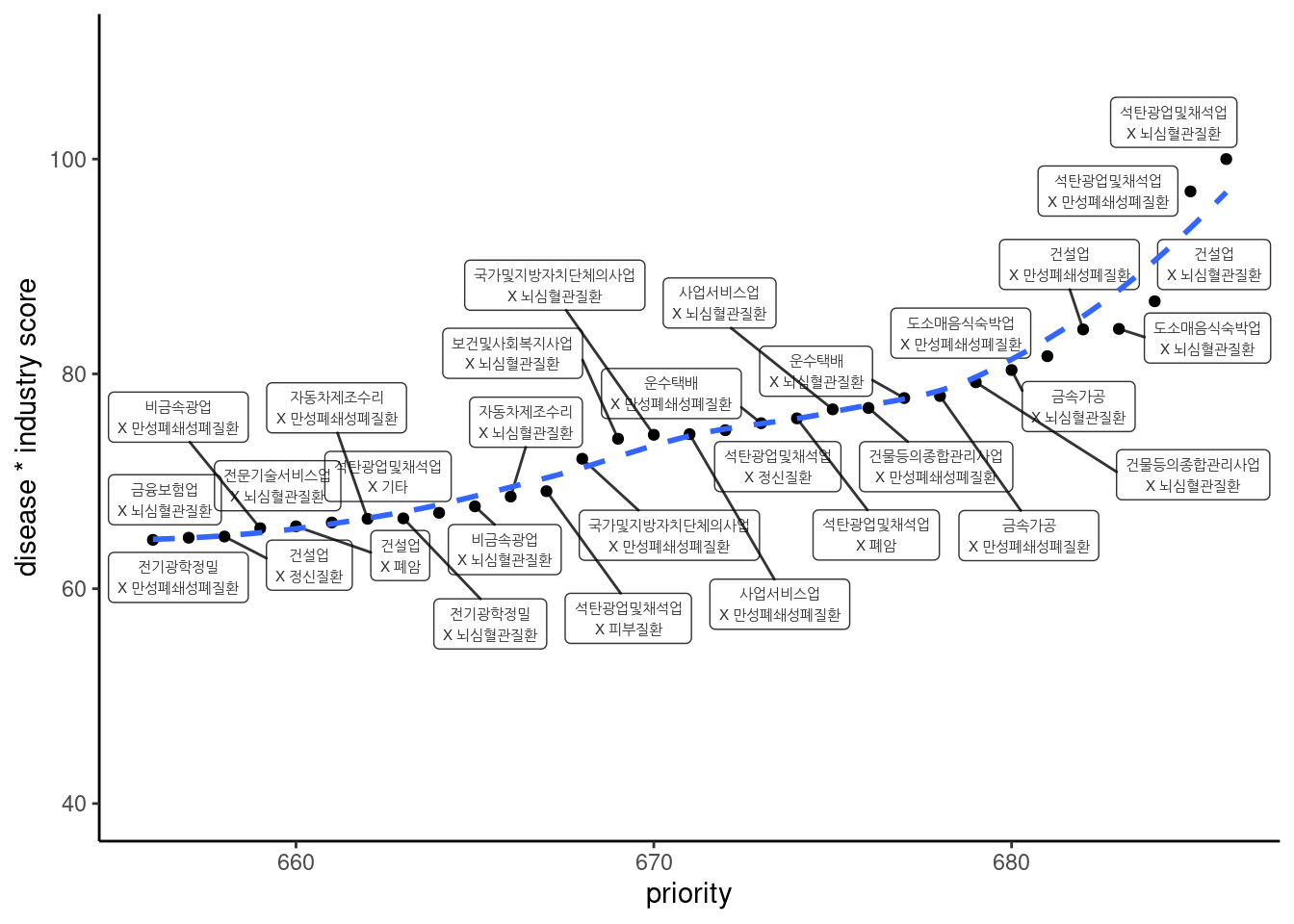 업종과 질병 점수를 합한 점수로 보기
업종과 질병 점수를 합한 점수로 보기
ds5 %>%
select(names, sc_ind_dz_sum) %>%
mutate(sc_ind_dz = round(sc_ind_dz_sum, 2)) %>%
arrange(desc(sc_ind_dz_sum)) %>%
datatable()ds5 %>%
select(names, sc_ind_dz_sum) %>%
mutate(sc_ind_dz = round(sc_ind_dz_sum, 2)) %>%
arrange(sc_ind_dz_sum) %>%
mutate(priority = row_number()) %>%
slice(656:686) %>%
ggplot(aes(priority, sc_ind_dz_sum)) +
geom_point()+
#geom_text(aes(label = names))+
geom_label_repel(aes(label = names), fill = NA,
alpha =0.8, size = 2) +
geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() + ylim(0, 3) + #xlim(450, 550)+
ylab("disease + industry score")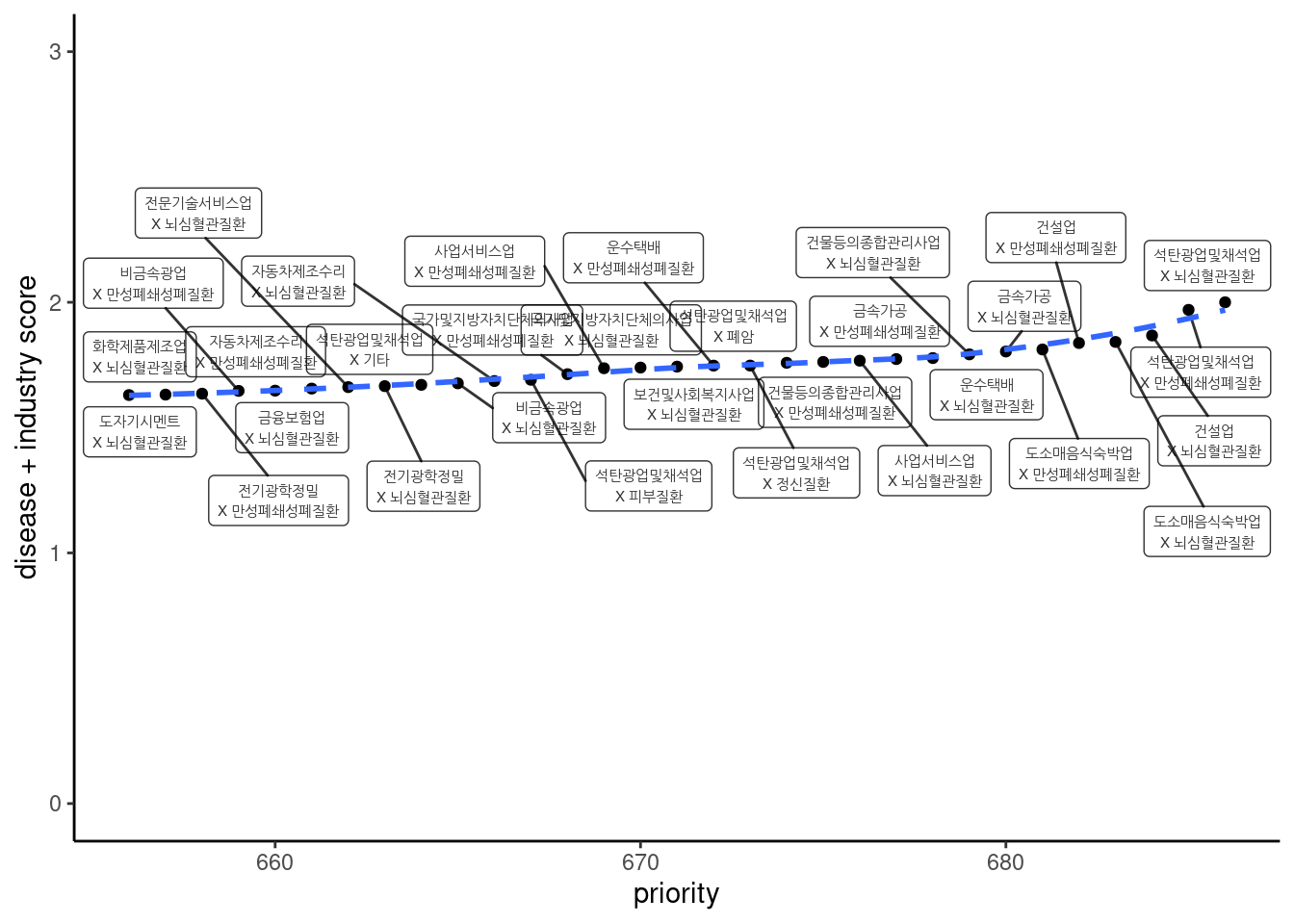
3.2.12 신청률비
신청률비의 점수와 그림(30위)는 다음과 같다.
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'## Warning: Removed 1 rows containing non-finite values (stat_smooth).## Warning: Removed 1 rows containing missing values (geom_point).## Warning: Removed 1 rows containing missing values (geom_label_repel).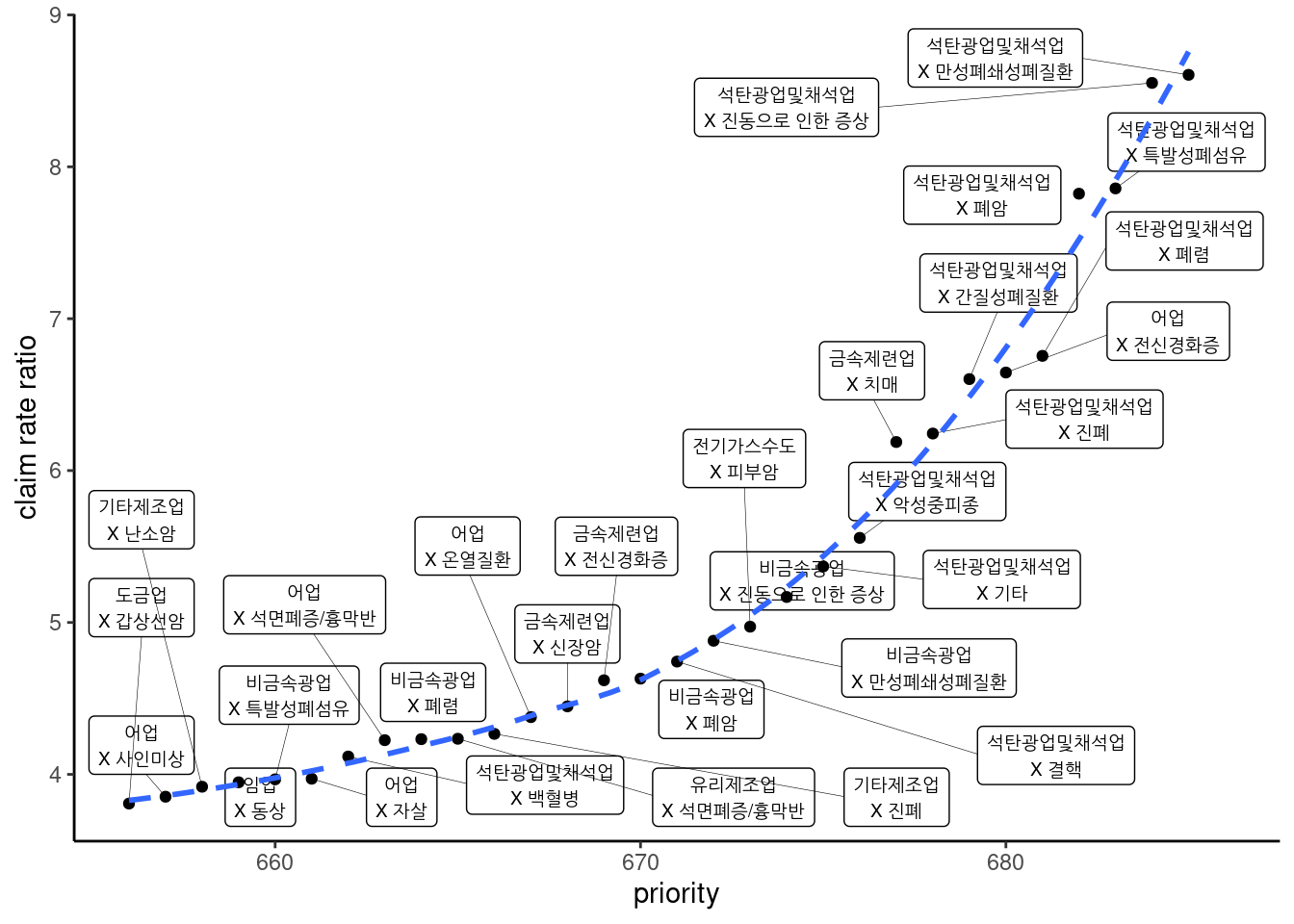
3.2.13 비례신청비
비례 신청비의 점수와 그림(30위)는 다음과 같다.
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'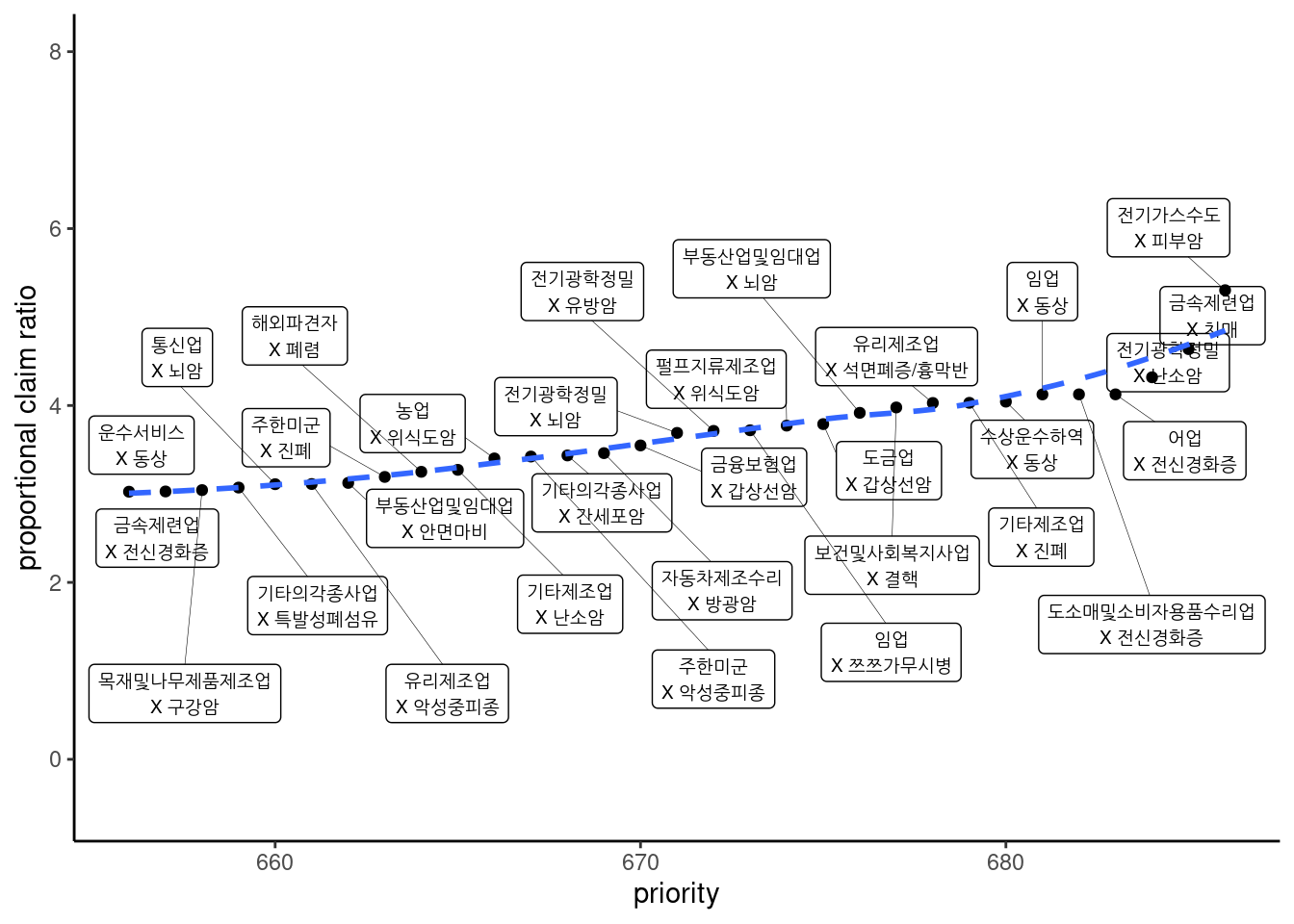
3.2.14 최종 점수
최종 점수는 업종점수 X 질병점수 X 비례신청비 X 신청률비 을 하였다. 따라서 100이 기준이며, 1000 나오는 경우 업종 질병 비례신청비를 고려하여 10배 우선순위를 갖는다고 판단할 수 잇다.
ds5 %>%
select(names, sc_ind_dz_pcr, crr) %>%
mutate(scores = sc_ind_dz_pcr * crr) %>%
mutate(scores = round(scores, 0)) %>%
arrange(desc(scores)) %>%
#slice(1:45) %>%
datatable()이를 2차원으로 표시할 수 있다. 즉 규모 (업종*질병 점수)와 특이도(비례신청비)로 구분하여 몇단개로 구분이 가능하다. 또한 실제 질병 신청수 (count)를 이용하여 질적 고려를 할 수 있다.
## Warning in self$trans$transform(x): NaN이 생성되었습니다## Warning: Transformation introduced infinite values in continuous y-axis## Warning: Removed 202 rows containing missing values (geom_point).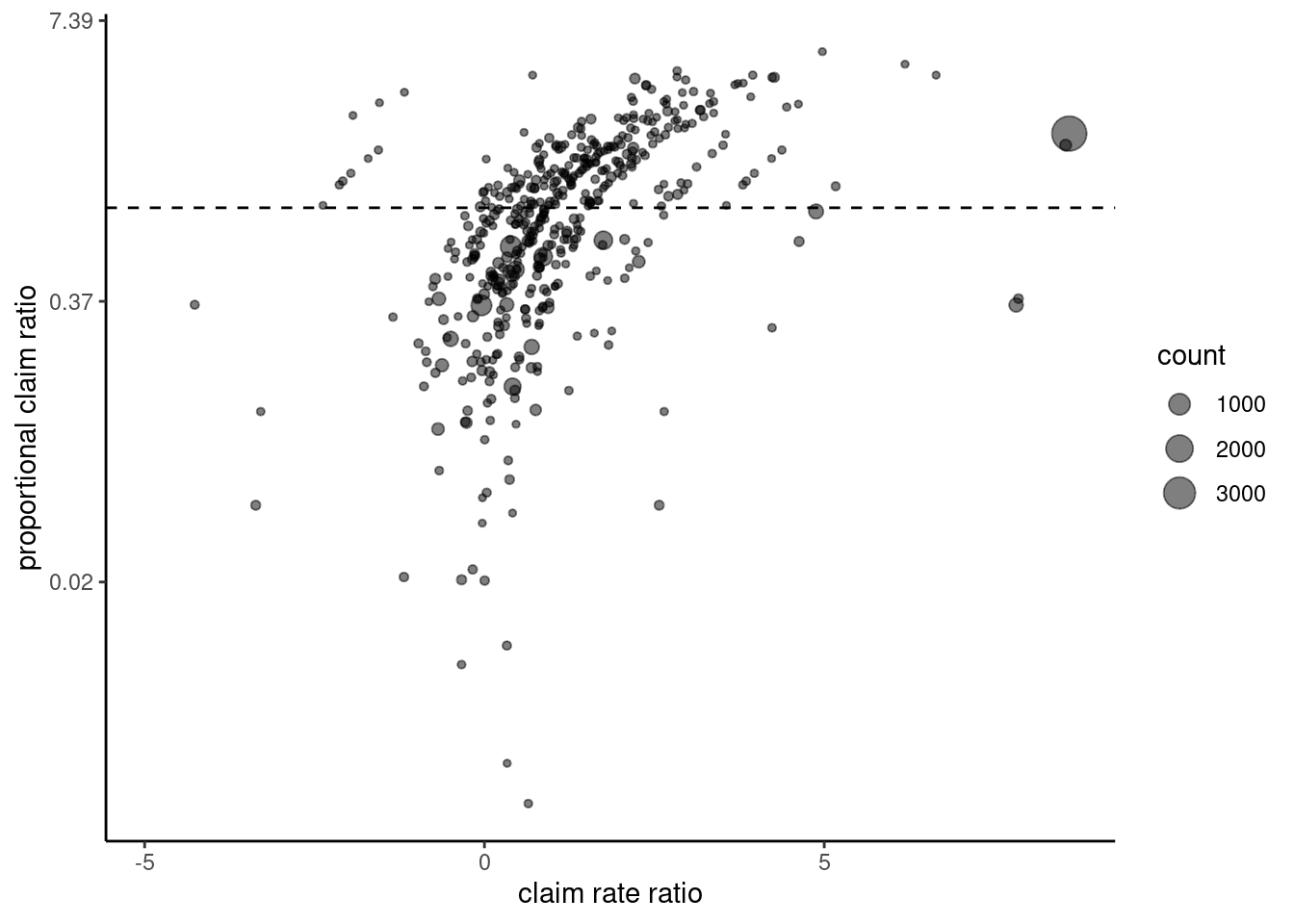
3.2.15 우선순위 집단
3.2.15.1 규모와 신청률비
신청률비를 중심으로 질병수를 고려하면 다음과 같다.
ds5 <- readxl::read_xlsx('data/claim/ds6.xlsx')
ds5 %>%
arrange((crr)) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = sc_ind_dz, y = crr, color = pcr )) +
geom_point(aes( size = count), alpha = 0.5) +
theme_classic() +
scale_x_continuous(trans='log',
labels = scales::number_format(accuracy = 0.01))+
scale_y_continuous(trans='log',
labels = scales::number_format(accuracy = 0.01))+
# geom_vline(xintercept = c(50), linetype =2, color ='red') +
# geom_hline(yintercept = c(1) , linetype =2, color ='red')+
# geom_vline(xintercept = c(25, 75), linetype =2, color ='grey', alpha = 0.5) +
# annotate(geom = 'text', x= c(75,25), y =20.5, label = rep(c('1', '2' )), size =20, color ='blue')+
# annotate(geom = 'text', x= c(75,25), y =0.1, label = rep(c('3', '4')), size =20, color ='grey')+
#geom_rect(aes(xmin=50,xmax=100,ymin=0,ymax=1000),alpha=0.002,fill="grey")+
# geom_rect(aes(xmin=50,xmax=100,ymin=1,ymax=1000),alpha=0.002,fill="red")+
xlab("score of industry and diseases") +
ylab("claim rate ratio") #+ ylim(c(-0.5, 6))## Warning: Removed 1 rows containing missing values (geom_point).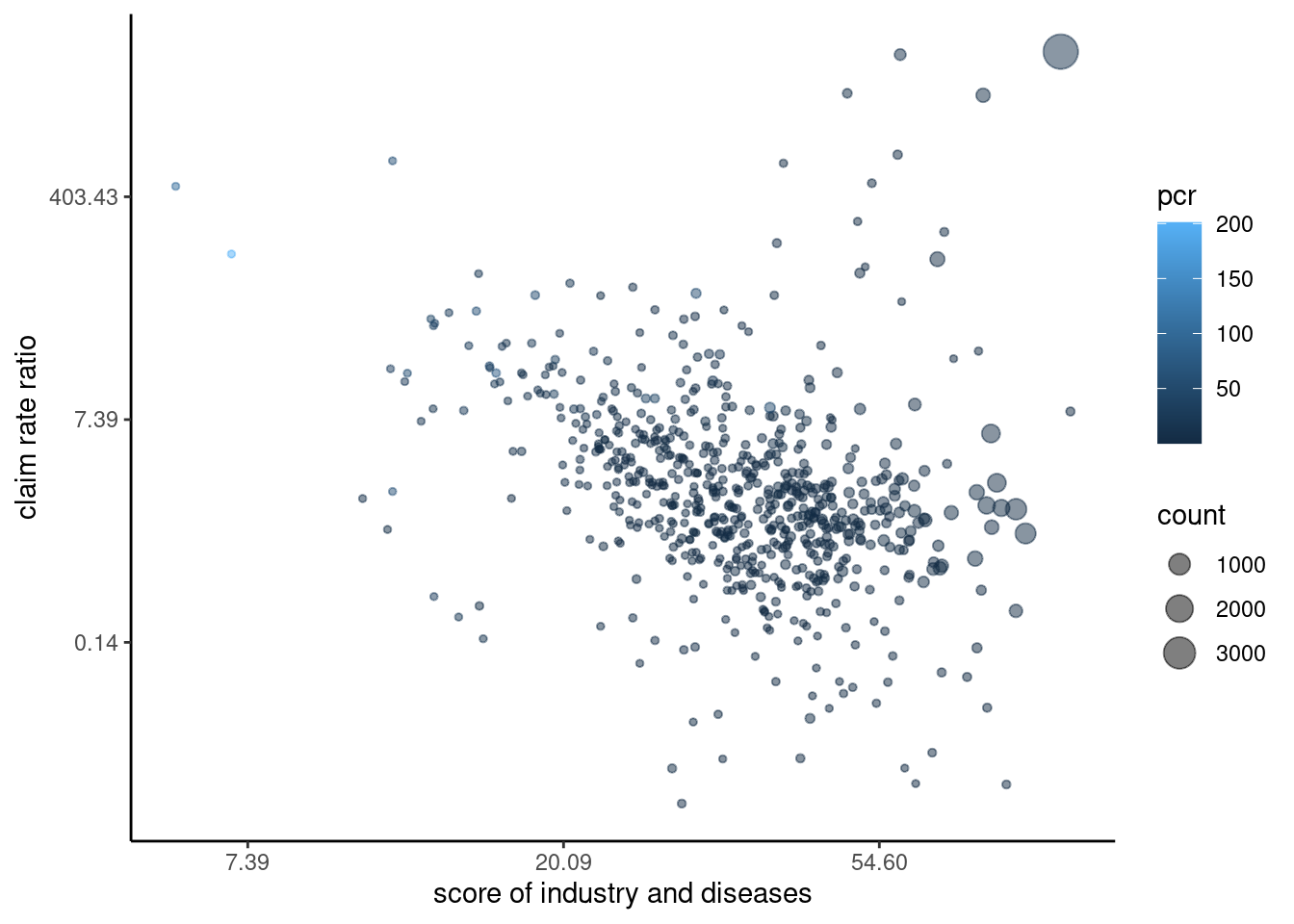
3.2.15.2 규모와 비례신청비
비례 신청비를 중심으로 질병수를 고려하면 다음과 같다.
ds5 <- readxl::read_xlsx('data/claim/ds6.xlsx')
ds5 %>%
arrange((pcr)) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = sc_ind_dz, y = pcr, color = crr )) +
geom_point(aes( size = count), alpha = 0.5) +
theme_classic() +
scale_x_continuous(trans='log',
labels = scales::number_format(accuracy = 0.01))+
scale_y_continuous(trans='log',
labels = scales::number_format(accuracy = 0.01))+
# geom_vline(xintercept = c(50), linetype =2, color ='red') +
# geom_hline(yintercept = c(1) , linetype =2, color ='red')+
# geom_vline(xintercept = c(25, 75), linetype =2, color ='grey', alpha = 0.5) +
# annotate(geom = 'text', x= c(75,25), y =20.5, label = rep(c('1', '2' )), size =20, color ='blue')+
# annotate(geom = 'text', x= c(75,25), y =0.1, label = rep(c('3', '4')), size =20, color ='grey')+
#geom_rect(aes(xmin=50,xmax=100,ymin=0,ymax=1000),alpha=0.002,fill="grey")+
# geom_rect(aes(xmin=50,xmax=100,ymin=1,ymax=1000),alpha=0.002,fill="red")+
xlab("score of industry and diseases") +
ylab("proportional claim ratio") #+ ylim(c(-0.5, 6))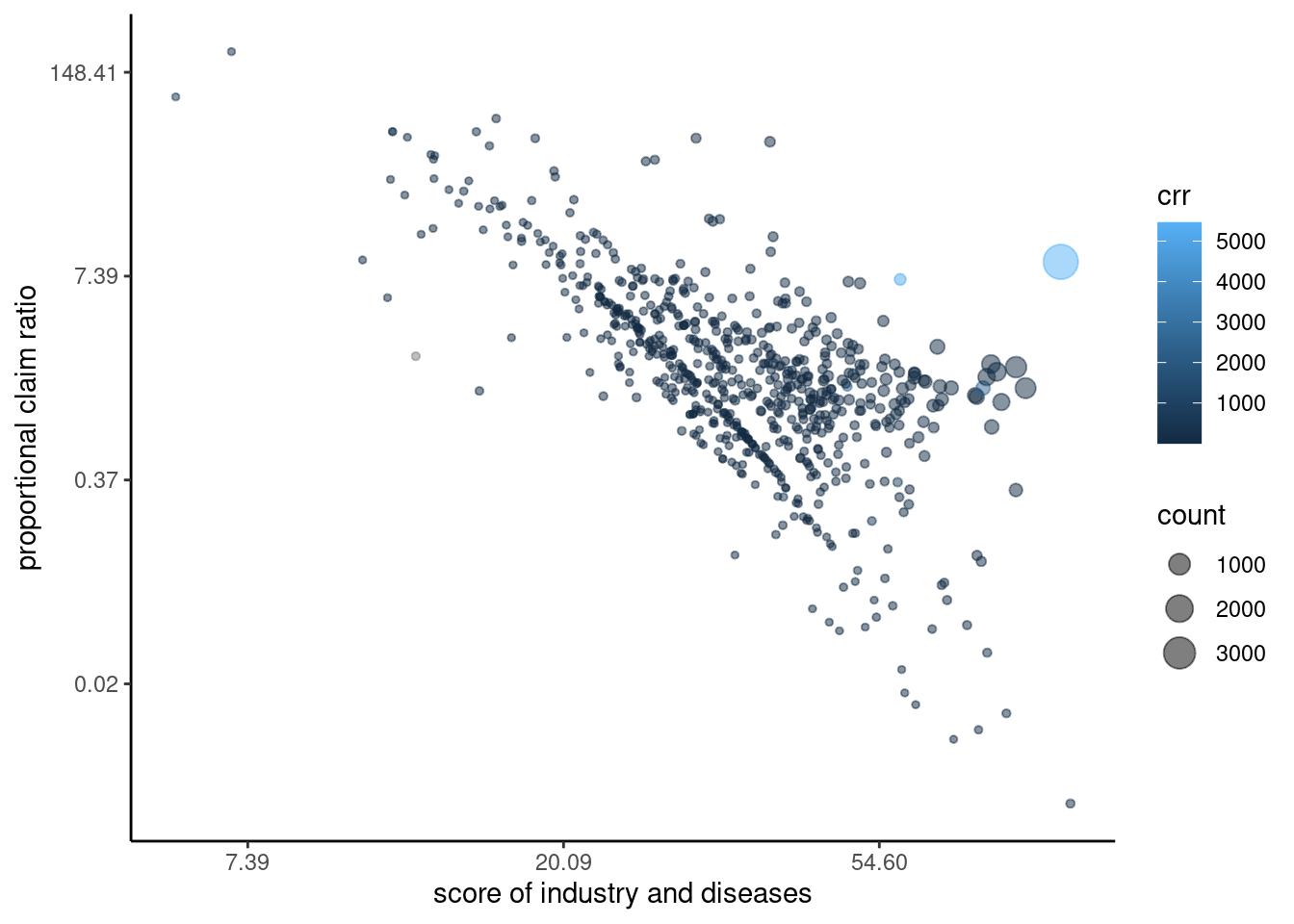
3.2.15.3 비례신청비와 신청률비
이를 2차원으로 표시할 수 있다. 즉 규모 (업종*질병 점수)와 특이도(비례신청비)로 구분하여 몇단개로 구분이 가능하다. 또한 실제 질병 신청수 (count)를 이용하여 질적 고려를 할 수 있다.
ds5 %>%
arrange((pcr)) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = log(crr), y = log(pcr), color = sc_ind_dz )) +
geom_point(aes( size = count), alpha = 0.5) +
theme_classic() +
# scale_y_continuous(trans='log',
# labels = scales::number_format(accuracy = 0.01))+
geom_vline(xintercept = c(0), linetype =2, color ='red') +
geom_hline(yintercept = c(0) , linetype =2, color ='red')+
geom_vline(xintercept = c(log(2)), linetype =2, color ='red') +
geom_hline(yintercept = c(log(2)) , linetype =2, color ='red')+
# geom_vline(xintercept = c(25, 75), linetype =2, color ='grey', alpha = 0.5) +
annotate(geom = 'text', x= c(3,-3), y =2, label = rep(c('1', '2' )), size =20, color ='blue')+
annotate(geom = 'text', x= c(3, -3), y =-2, label = rep(c('3', '4')), size =20, color ='grey')+
#geom_rect(aes(xmin=50,xmax=100,ymin=0,ymax=1000),alpha=0.002,fill="grey")+
# geom_rect(aes(xmin=50,xmax=100,ymin=1,ymax=1000),alpha=0.002,fill="red")+
xlab("claim rate ratio") +
ylab("proportional claim ratio") #+ ylim(c(-0.5, 6))## Warning: Removed 1 rows containing missing values (geom_point).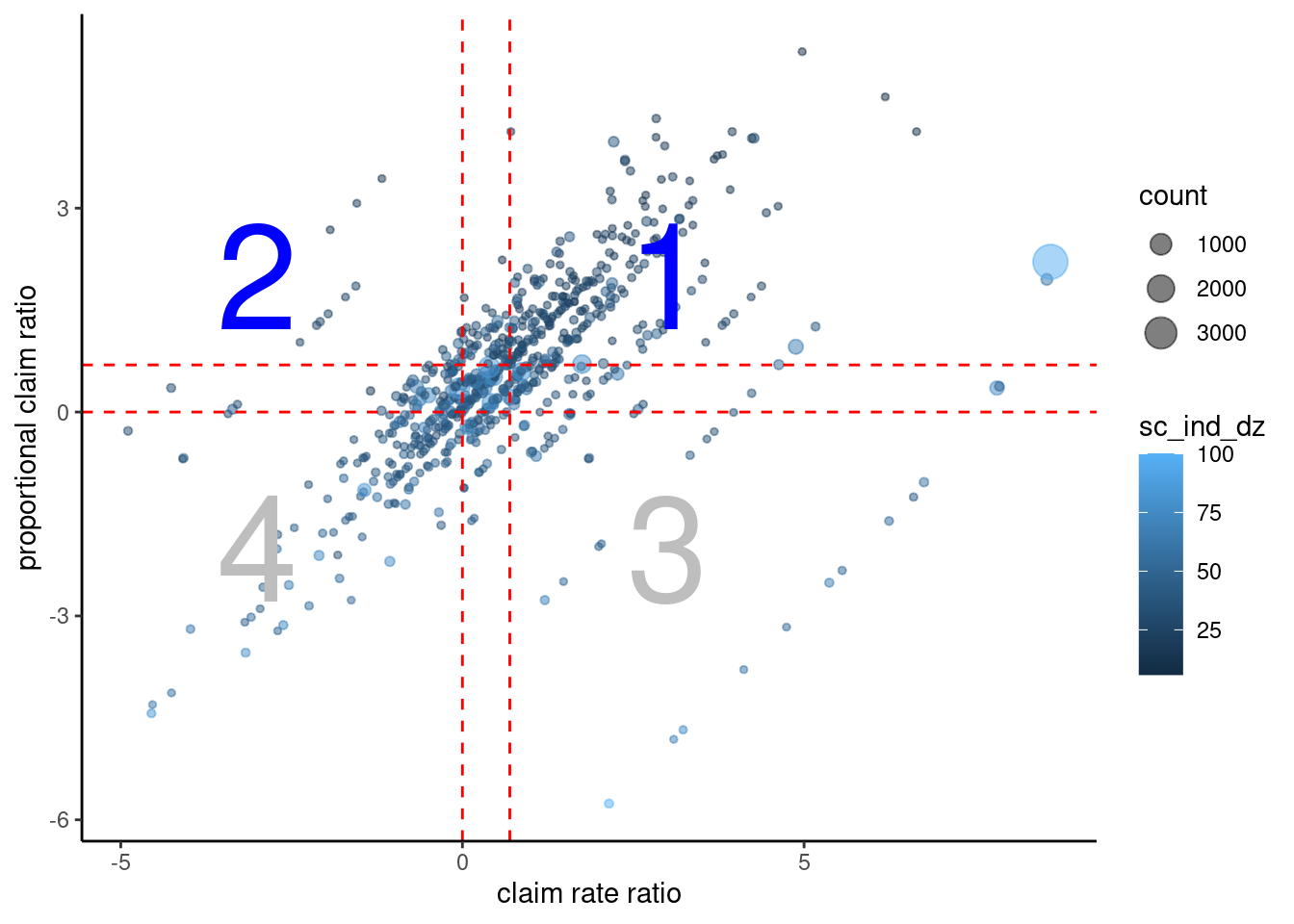
3.2.16 우선 순위 집단별 관찰
3.2.16.1 우선순위 집단 구별
ds5 <- ds5 %>%
mutate(gps = ifelse(crr >2 & pcr >2, 1.1,
ifelse(crr>1 & pcr >1, 1.2,
ifelse(crr<1 & pcr >1, 2,
ifelse(crr>1 & pcr<1, 3,
4)))))535개의 조합이 있었다. 이에 규모와 특성별 우선순위 집단을 4 집단으로 나눌 수 있고, 이중 강도를 고려하여 2개 집단식 총 8개 집단을 구별하였다.
| 번호 | 규모 | 비례신청비 | 특징 |
|---|---|---|---|
| 1-1 | 신청률비가 2 이상 | 비례신청비가 2 이상 | 첫번재-1 우선순위를 갖는다 |
| 1-2 | 신청률비가 1 이상 | 비례신청비가 1 이상 | 첫번재-2 우선순위를 갖는다 |
| 2 | 신청률비가 1 이하비례신청비가 1이상 | 두번째 우선순위를 갖는다 | |
| 3 | 신청률비가 1 이상 | 비례신청비가 1이하 | 세번재 우선순위를 갖는다 |
| 4 | 신청률비가 1 이하 | 비례신청비가 1이하 | 네번재 우선순위를 갖는다 |
3.2.16.2 1-1 번집단
fig1.1 <-ds5 %>%
filter(gps ==1.1) %>%
filter(count >3) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = log(crr), y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("claim rate ratio")+
ylim(c(-0, 4)) + xlim(c(0, 4)) +
ggtitle(" 1-1번 집단")
fig1.1## Warning: Removed 7 rows containing missing values (geom_point).## Warning: Removed 7 rows containing missing values (geom_label_repel).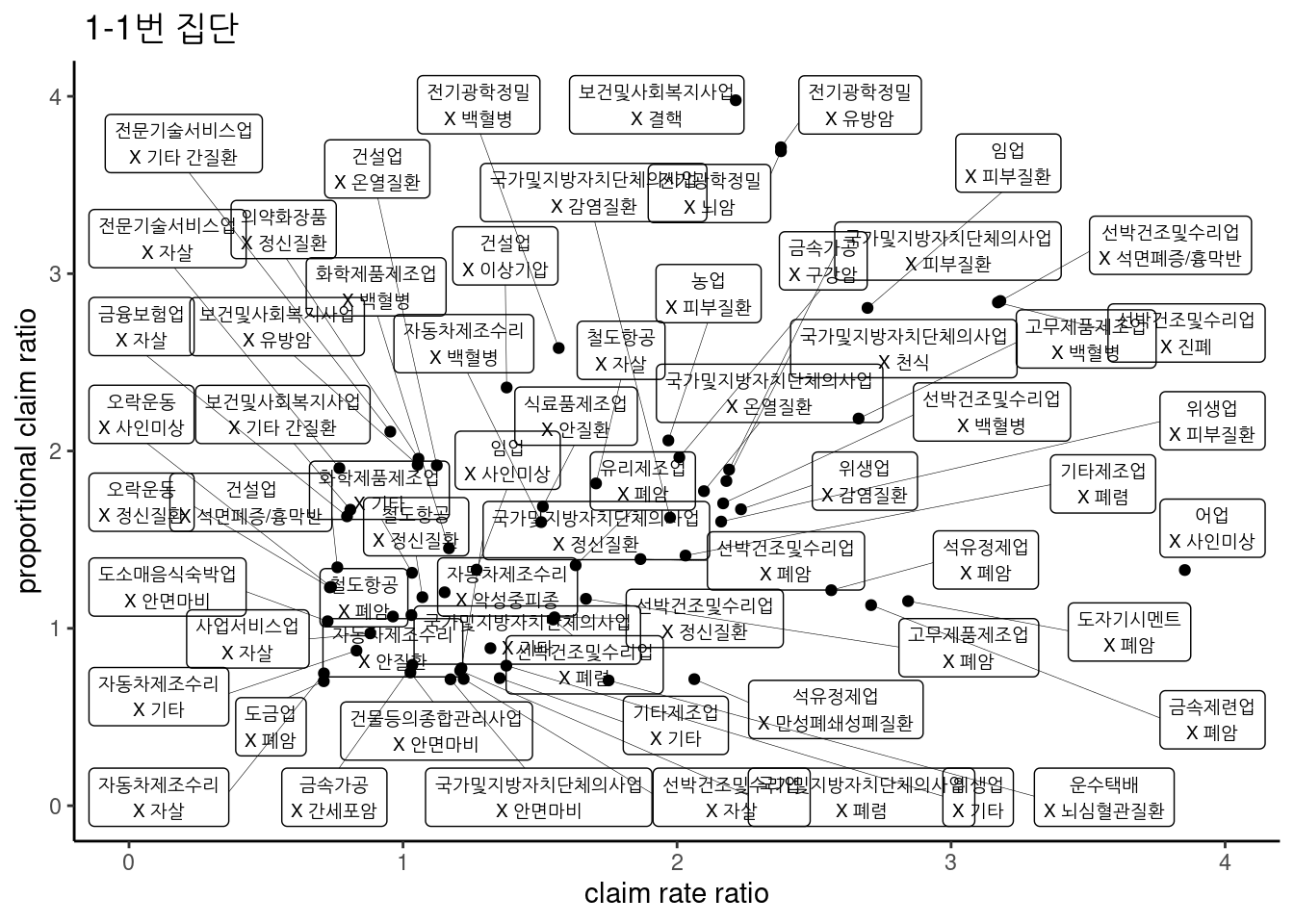
3.2.16.3 2 번집단
2번 집단은 매우 많아 10건 초과 건 수만 표시하였다.
ds5 %>%
filter(gps == 1.2) %>%
filter(count >10) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = log(crr), y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("claim rate ratio")+
ylim(c(-0.9, 5)) + xlim(c(0, 4)) +
ggtitle(" 2번 집단") ## Warning: Removed 2 rows containing missing values (geom_point).## Warning: Removed 2 rows containing missing values (geom_label_repel).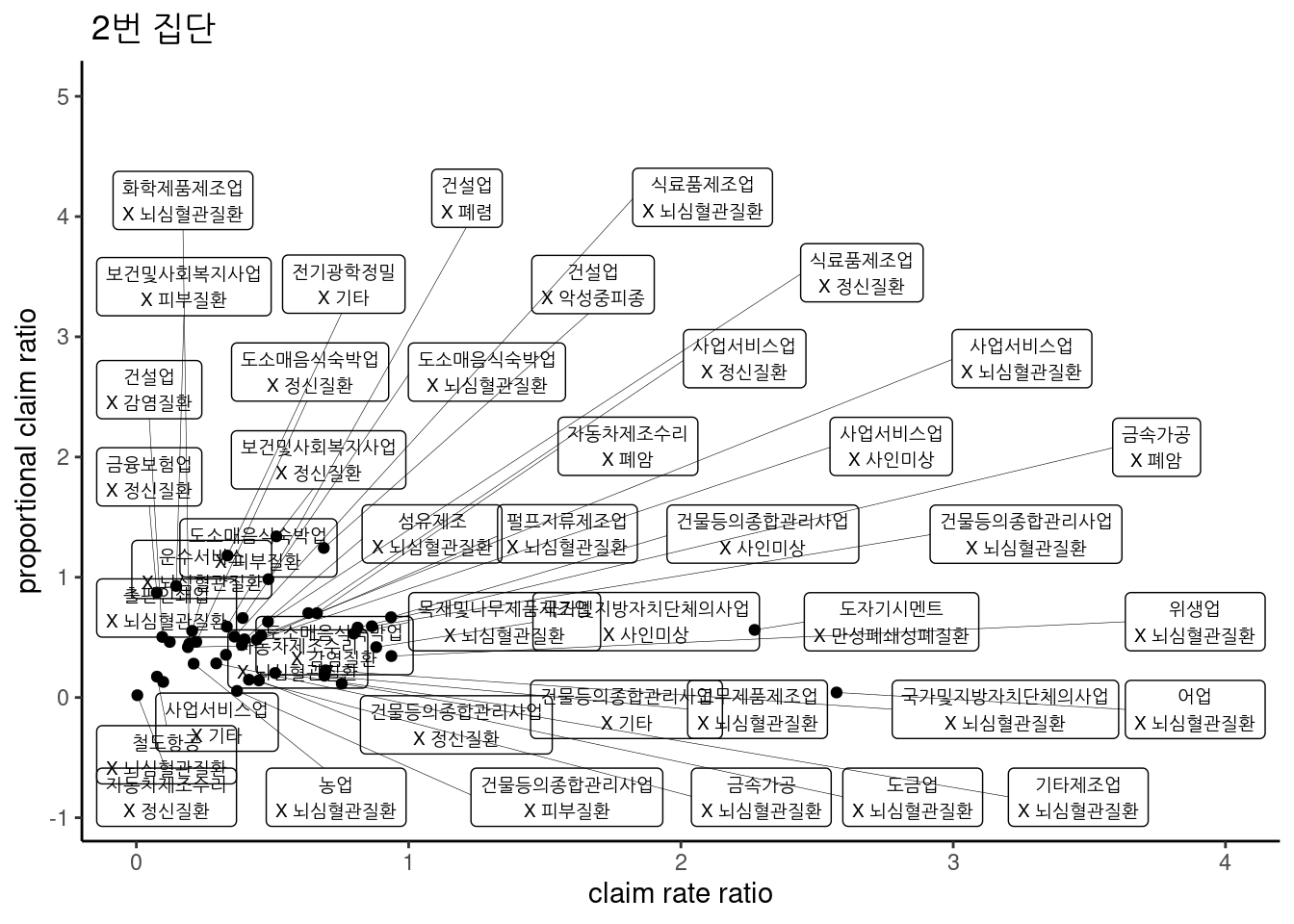 #### 2 번집단
#### 2 번집단
ds5 %>%
filter(gps == 2) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = log(crr), y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("claim rate ratio")+
#ylim(c(-6, 1)) + xlim(c(40, 100)) +
ggtitle(" 2번 집단") 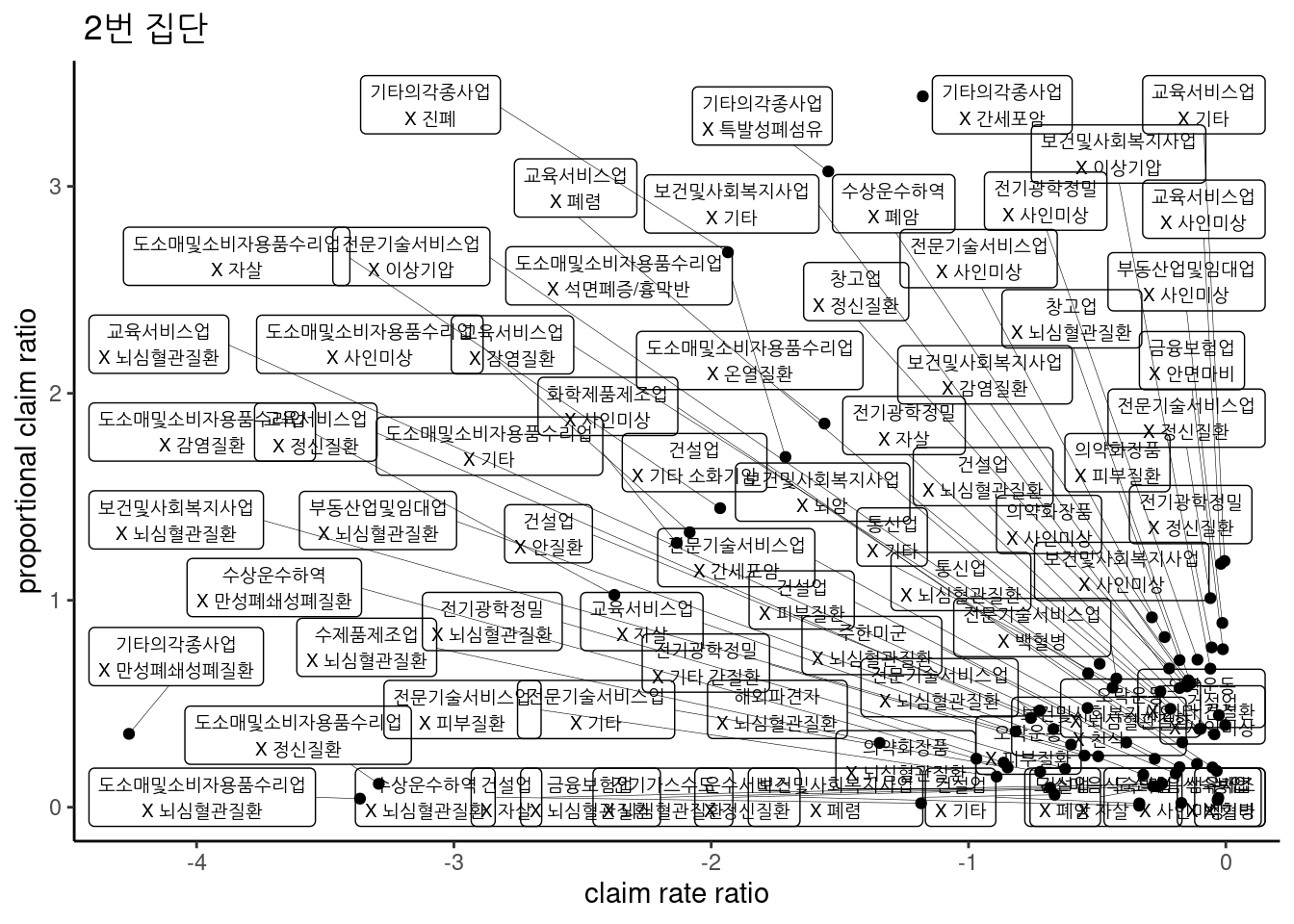
3.2.16.4 3 번집단
ds5 %>%
filter(gps == 3) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = log(crr), y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("claim rate ratio")+
#ylim(c(-6, 1)) + xlim(c(40, 100)) +
ggtitle(" 3번 집단") 
3.2.16.5 4 번집단
4번 집단도 매우 많아 3건 이상만 표시하였다.
ds5 %>%
filter(gps == 4, count >3) %>%
#slice(490:535) %>%
ggplot(aes(x = sc_ind_dz, y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("claim rate ratio")+
#ylim(c(-0.9, 2.5)) + xlim(c(40, 100)) +
ggtitle(" 4번 집단") 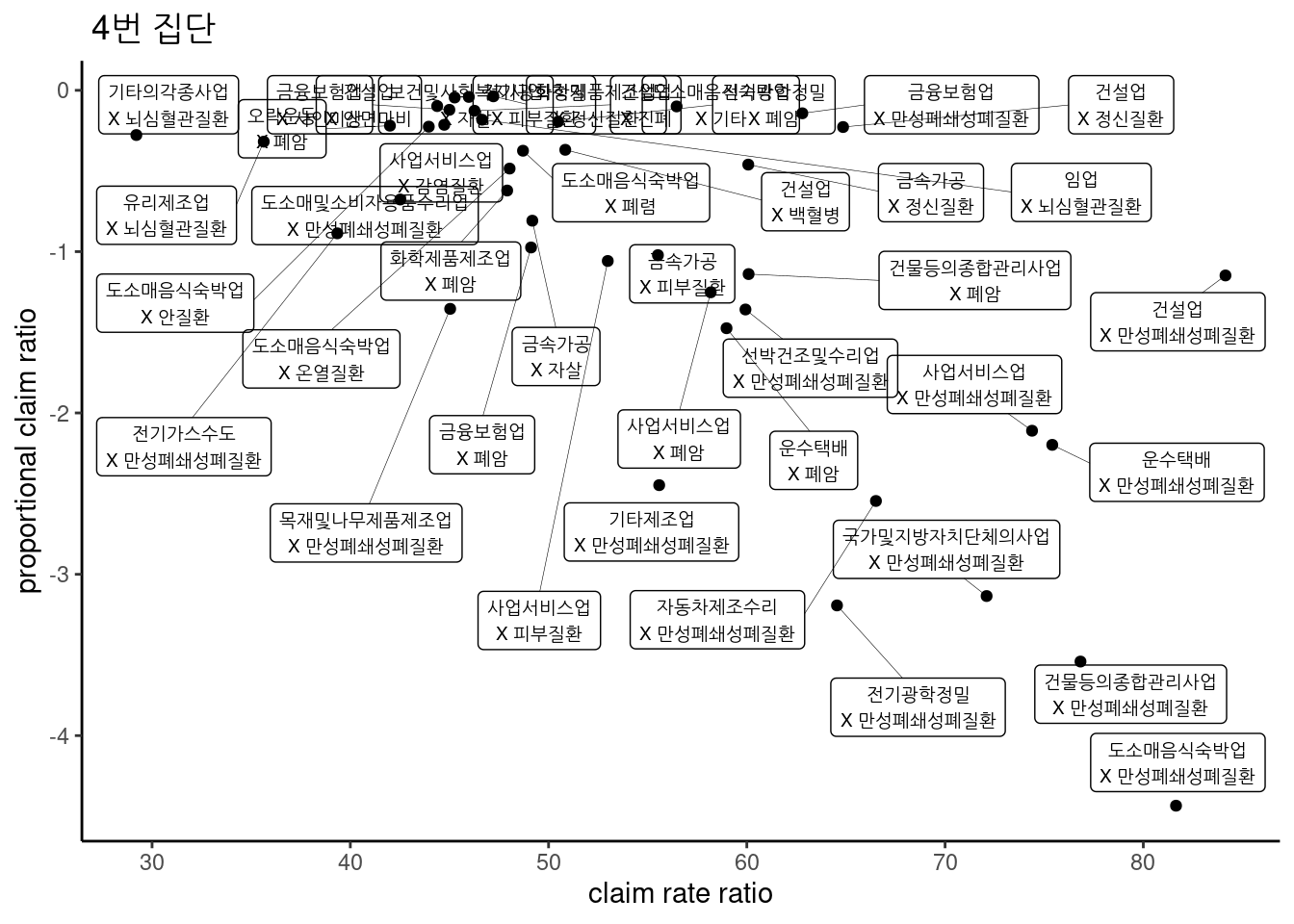
3.2.16.6 특이도 강조 1
ds5 %>%
filter(pcr/crr >2 & crr >1) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = sc_ind_dz, y = log(pcr) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio") +
xlab("score of industry and diseases")+
#ylim(c(-0.9, 2.5)) + xlim(c(40, 100)) +
ggtitle(" 신청률비 대비 비례신청비가 높은 경우") 
3.2.16.7 특이도 강조 2
산재신청률비와 비례신청비 모두 높은 경우를 점수화함.
ds5%>%
mutate(zx = pcr * crr ) %>%
arrange(desc(zx)) %>%
select(names, zx) %>%
slice(1:50) %>%
datatable() ds5 %>%
mutate(zx = pcr *crr ) %>%
filter(count >20) %>%
#mutate(priority = row_number()) %>%
#slice(490:535) %>%
ggplot(aes(x = sc_ind_dz, y = log(zx) )) +
geom_point() +
geom_label_repel(aes(label = names), fill = NA,
alpha =1, size = 2.5,
box.padding = 0.4,
segment.size =0.1,
force = 2) +
#geom_smooth(se = FALSE, linetype = 'dashed')+
# geom_abline(intercept = 0, slope = 1/(30.1), color="red",
# linetype="dashed", size=1)+
theme_classic() +
ylab("proportional claim ratio * claim rate ratio") +
xlab("score of industry and diseases")+
#ylim(c(-0.9, 2.5)) + xlim(c(40, 100)) +
ggtitle(" 신청률비과 비례신청비가 모두 높은 경우") 
3.2.17 질적 우선순위 고려
연구진 회의를 검토한 결과 몇가지 질적 고려사항이 있었다. 본 연구는 예방 우선순위가 아니라 조사 우선순위이다. 이미 잘알려진 연구는 조사 우선순위에서 밀려날 수 있으며, 사용할 수 있는데이터가 건강보험공단 자료와 특수건강검진 자료이므로 사회심리적 요소 사용 불가능 등이 있다. 또한 이미 보상 수준의 단계를 받고 있는 진폐, copd, 소음성 난청등은 제외 할 수 있다. 여기에 진폐와 폐암의 관계인 광업-폐암 등도 제외 될 수 있다.
| 항목 | 내용 | 비고 |
|---|---|---|
| 추정효과 | 조사 실효성1 | 이미 학문적 근거가 충분한 경우 (IARC group 1) |
| 추정효과 | 조사 실효성2 | 이미 사회적 합의가 있는 경우 (장시간 근무 뇌심혈관) |
| 실행가능성 | 빅데이터 활용 | 물리화학 위주의 빅데이터의 활용 고려 (사회심리요소 불가능) |
| 실행가능성 | 진단명 부정확 | 사인미상 등 진단명 부정확 제외 |
| 예방가능성 | 보상 단계 고려 | 진폐, COPD, 소음성 난청 등 직업병의 경우 |
| 사회적이슈 | 형평성 제고 | 질병 특성상 취약 집단 발굴 필요 (동상, 자살) |
| 사회적이슈 | 질병 분포의 이질성 | 특정 업종에 취우친 산재 신청 (PCR 강조) |
| 사회적이수 | 취약집단 | 잘 알려진 원인 질병이나 취약 집단 발굴이 필요한 경우 |
이에 따라 IARC 등 근거수준 (medical_evidence, me), 추정원칙적용여부(social_causal, sc),
사회 심리학, 인강고학적 추가 자료 구축후 조사 가능한 것(OutofData, od)을 고려하여 우선순위를 선정하였다.
3.2.17.1 질병 분포의 이질성 점수
특정 집단에서 더 많은 분포를 보임, 정규성을 벗어나는 정도
qfdat <- readxl:: read_xlsx('data/claim/fdat_quality.xlsx')
qfdat <- qfdat %>%
mutate(zx = crr * pcr)
stds_dat <- qfdat%>%
group_by(disease) %>%
summarize(med = median(zx),
avg = mean (zx),
std = sd(zx)) %>%
mutate(stds = ifelse(is.na(std) , max(std, na.rm = TRUE), std) )
qfdat1 <- qfdat %>%
left_join(stds_dat , by = c('disease')) %>%
mutate(jhs = zx * stds) %>%
ungroup() %>%
arrange(desc(jhs))
openxlsx::write.xlsx(qfdat1, "data/claim/qfdat1.xlsx", overwrite = TRUE)std_fig <-qfdat1 %>%
select(disease, jhs) %>%
group_by(disease) %>%
#filter(!disease %in% c('만성폐쇄성폐질환', '뇌심혈관질환', '사인미상')) %>%
ggplot(aes( x= jhs)) + geom_density()+
facet_wrap(disease~., ncol = 5, scales = 'free')+
theme(legend.position = "none",
panel.grid = element_blank(),
axis.title = element_blank(),
axis.text.y = element_blank())
ggsave(std_fig, file="figures/std_fig.png", width=6, height=8, dpi=300)## Warning: Removed 1 rows containing non-finite values (stat_density).## Warning: Groups with fewer than two data points have been dropped.## Warning in max(ids, na.rm = TRUE): max에 전달되는 인자들 중 누락이 있어 -Inf를
## 반환합니다 질병이 몇몇 업종에서 취중되는 경우이면서 이미 산업재해 보상보험에서 추정의 원칙을 적용하고 있는 것은
질병이 몇몇 업종에서 취중되는 경우이면서 이미 산업재해 보상보험에서 추정의 원칙을 적용하고 있는 것은 만성폐쇄성폐질환, 석면폐증, 악성중피종, 진동의로 인한 증상, 진폐, 특발성 폐섬유 폐렴, 폐암 등 이다. 따라서 상기 질환은 제외 할 수 있겠다.
구강암, 신장암, 온열질환, 피부질환 중에는 신장암이 TCE로 인한 IARC group 1이라면 제외, 구강암이 formaldehyde (IARC group ) 인 경우는 제외할 수 있고, 온열질환이나 피부질환은 취약집단이있다는 전제하에 제외하지 않았다.
3.2.17.2 의학적 근거 순위 질적 고찰 방법
역학적 정보 유형을 통해 점수를 제공하고, 정보 수준에 따라 향후 역학 연구 방법이나 추가 연구에 대한 지식을 제공할 수 있다. 여기서 IARC나 Review 연구가 충분히 이루어진 경우는 제외하는 방법을 사용하였다.
추후 *예를 들어 신장 질환 - 결정형 유리규산의 경우 코호트 연구 2개 유의, 환자 대조군 연구 2개 유의 하여 역학 연구의 점수는 3점, 이때 중간 이상의 양의 상관관계로 가중 점수 0.6점을 합산해 줄 수 있다.

“신장 질환 결정형 유리 규산”
| 결정형 유리 규산에 의한 신장 질환 |
|---|
| 1990년에 325명의 말기신부전 환자-대조군 연구에 따르면 직업에 의해 유리 규산에 노출된 경우 상대위험도 1.67을 보였고, 특히 벽돌공장에서 일한 경우 1.92, 모래를 이용한 세척업무를 한 경우 3.83을 보였다. 2001년 미국의 연구, 모래를 다루는 산업에 종사하는 4626명의 코호트 대상자는 표준 미국 인구와 비교하면 급성 신장 질환에 2.61(1.49-4.24) 표준사망비, 만성 신장 질환 1.61(1.13-2.22) 표준사망비, 관절염에 4.36(2.76-6.54) 표준사망비를 보였다. 또한, 말기신부전증 1.97(1.25-2.96) 표준 발생비, 사구체신염 3.85(1.55-7.93)의 표준 발생비를 보였다. 그리고 류마티스 관절염에서 양의 노출-반응 추세를 보였다 1997년 적어도 1년 이상 금광에서 일한 2412명의 광부를 대상으로 한 후향적 코호트연구에서 11명의 코호트 구성원이 말기신부전을 치료받았으며, 이는 표준 인구대비 1.37(0.68-2.46)의 표준 발생률을 보였다. 또한, 10년 이상 일했을 경우 말기신부전 표준 발생률은 7.70(1.59-22.48)을 보였다. 이 연구는 유리 규산에 노출되는 것이 말기신부전의 위험을 증가시키며 특히 사구체신염에 의한 말기신부전이 늘어난다고 설명한다. 한 병원에서 연구한 환자-대조군 연구에 따르면 ANCA(+) 급성진행 토리콩팥염과 유리 규산에 직업적 노출과 연관성이 있다. 환자군은 대조군과 비교하면 14(1.7-113.8)의 상대 위험도를 보였으며, p-ANCA와 anti-MPO 항체와 연관성이 있었다 |
| Steenland NK, Thun MJ, Ferguson CW, Port FK. Occupational and other exposures associated with male end-stage renal disease: a case/control study. Am J Public Health 1990;80(2):153-7. |
| Steenland K, Sanderson W, Calvert GM. Kidney disease and arthritis in a cohort study of workers exposed to silica. Epidemiology 2001;12(4):405-12. |
| Calvert GM, Steenland K, Palu S. End-stage renal disease among silica-exposed gold miners. A new method for assessing incidence among epidemio-logic cohorts. JAMA 1997;277(15):1219-23. |
3.2.18 질병군 제외
질병이 불명확하거나 업종이 불명확하여 의학적 근거 수준 검토가 어려운 경우를 제외 하였다. IARC나 Review 가 이미 충실한 조합을 제외하였다. 총 686개 중에 503개의 조합이 사라져, 183개가 남았다. 이중 갑상선암의 경우 최근 건강검진에서 조기 발견되는 요소에 대한 평가가 결정되지 않은 문제가 있다. 따라서 방사선에 의한 갑상선은 사전조사를 할 필요가 있으나 이외 방사선 노출이 의심되지 않는 업종에서의 갑상선암은 제외하도록 하겠다. 따라서 4개가 더 제외된 179개 조합이 남았다. 여기에 사인 미상 39개가 제외된 140개로 요약 되었다.
qfdat2<- qfdat1 %>%
mutate(medical_evidence = me) %>%
filter(!disease %in% c('기타', '사인미상')) %>%
filter(!industry %in% c('기타')) %>%
filter(!medical_evidence %in% c('IARC', 'review')) %>%
filter(!(disease %in% c('갑상선암') &
industry %in% c('도금업','금융보험업','운수택배', '사업서비스업')))dat <-qfdat2%>%
mutate(pr = rank(jhs)/length(jhs)*100) %>%
mutate(pr = round(pr, 0)) %>%
mutate (scores = (log(jhs)))
dat %>%
select(pr, scores, industry, disease) %>%
datatable() %>% formatRound('scores', digits = 2)summary(dat$pcr)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.04224 1.34877 2.86119 9.23888 5.64195 201.01351summary(dat$scores)## Min. 1st Qu. Median Mean 3rd Qu. Max.
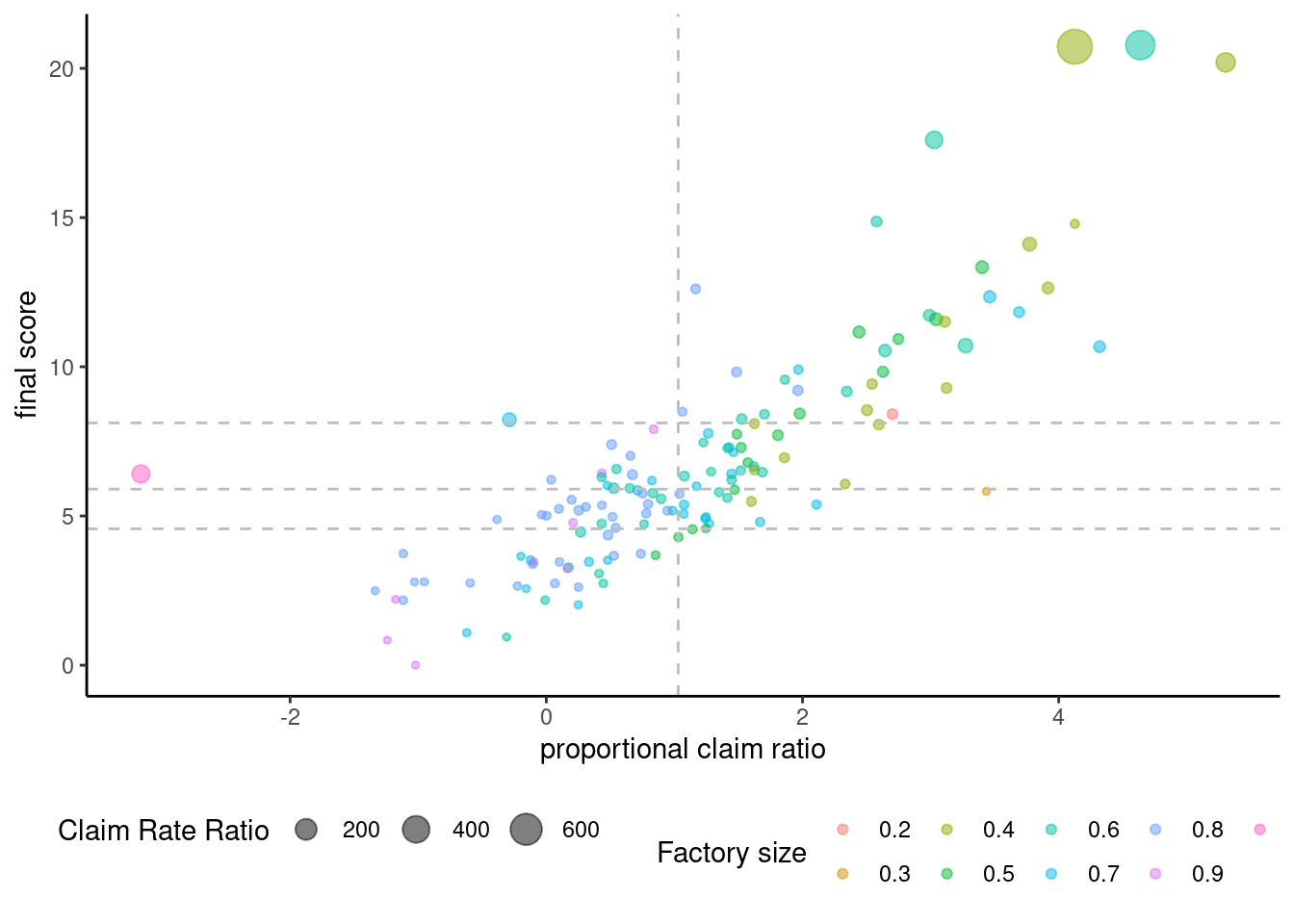
## 0.000006 4.573174 5.903456 6.665145 8.126830 20.780689dat<-dat %>%
mutate(gps2 = ifelse(scores >summary(dat$scores)[5], 1,
ifelse(scores >summary(dat$scores)[3], 2,
ifelse(scores >summary(dat$scores)[2], 3, 4)))) dat %>%
ggplot(aes(x= log(pcr), y = scores,
color = as.factor(round(sc_ind,1)))) +
geom_point(aes( size = crr), alpha = 0.5) +
theme_classic() +
# scale_y_continuous(trans='log',
# labels = scales::number_format(accuracy = 0.01))+
geom_vline(xintercept = c(log(2.8)), linetype =2, color ='grey') +
geom_hline(yintercept = c(4.57, 5.90, 8.12), linetype =2, color ='grey')+
# geom_vline(xintercept = c(25, 75), linetype =2, color ='grey', alpha = 0.5) +
# annotate(geom = 'text', x= c(4,-2), y =15, label = rep(c('1', '2' )), size =20, color ='blue')+
# annotate(geom = 'text', x= c(4, -2), y =5, label = rep(c('3', '4')), size =20, color ='grey')+
#geom_rect(aes(xmin=50,xmax=100,ymin=0,ymax=1000),alpha=0.002,fill="grey")+
# geom_rect(aes(xmin=50,xmax=100,ymin=1,ymax=1000),alpha=0.002,fill="red")+
xlab("proportional claim ratio") +
ylab("final score") #+ ylim(c(-0.5, 6)) 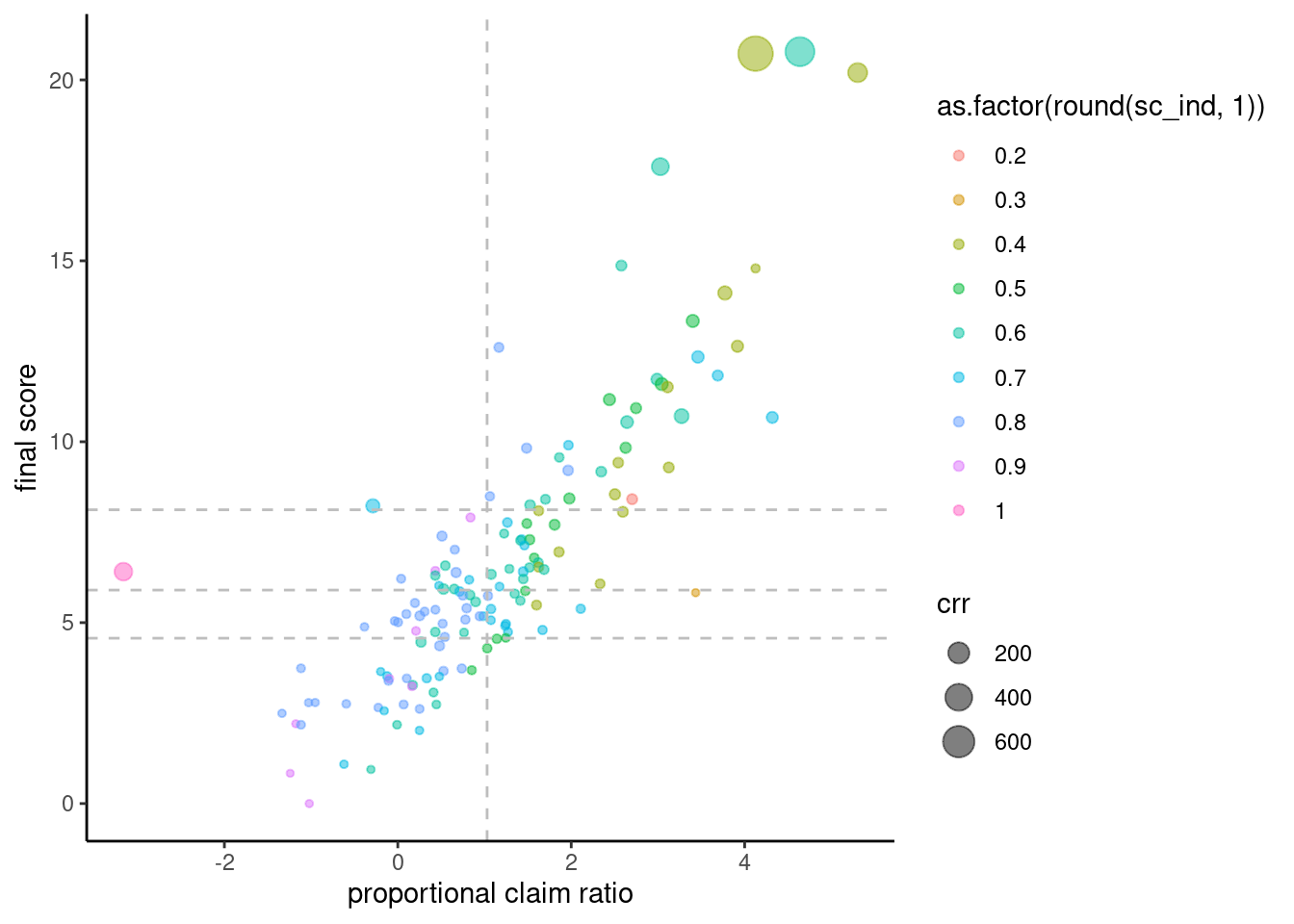
3.2.19 최종 우선 순위 점수
3.2.19.1 score 1 군 우선순위
최종 score에 따른 1군 우선 순위는 아래와 같다.
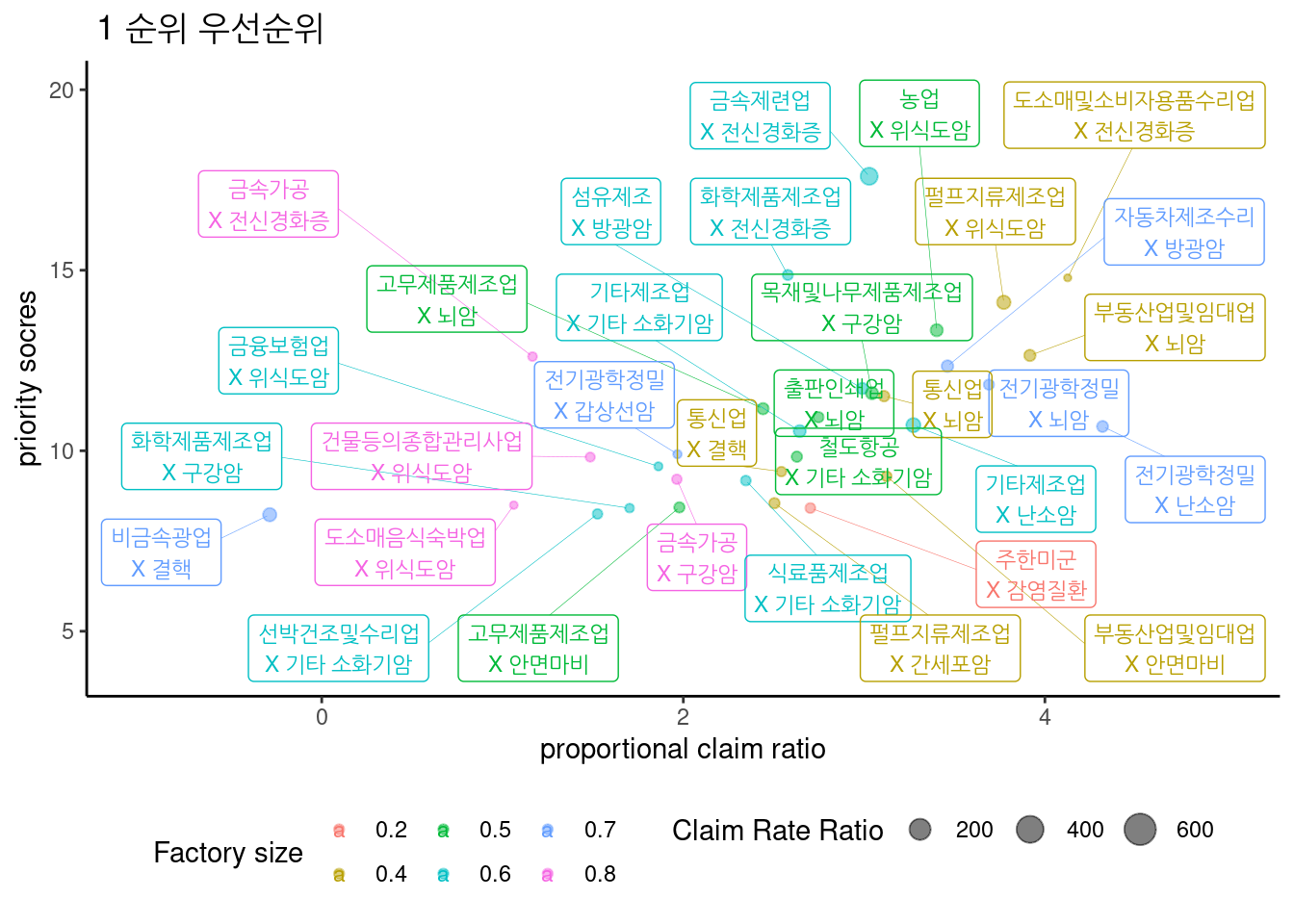
표는 아래와 같다.
3.2.19.2 score 2 군 우선순위
최종 score에 따른 1군 우선 순위는 아래와 같다.
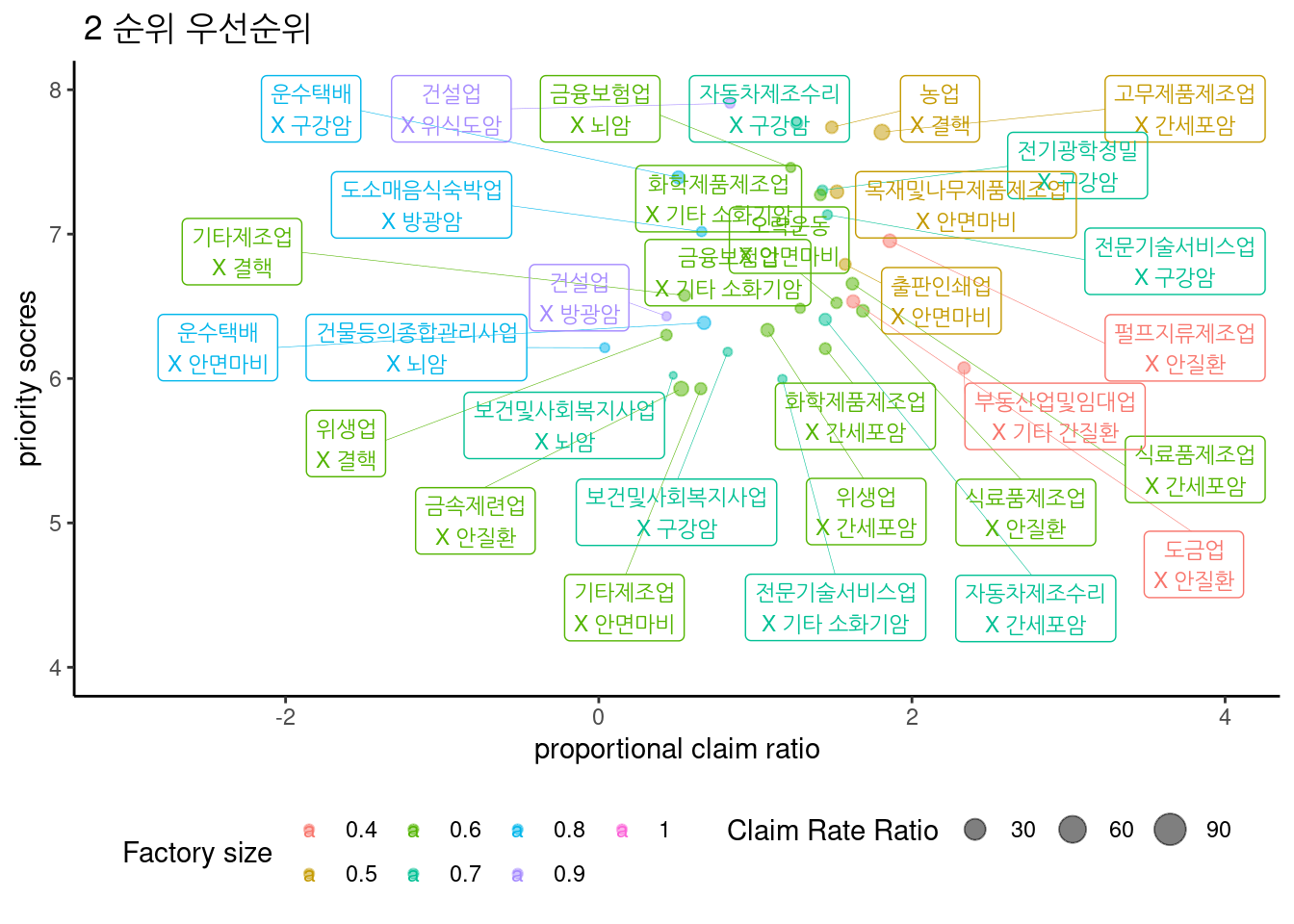
표는 아래와 같다.
3.2.19.3 score 3 군 우선순위
최종 score에 따른 3군 우선 순위는 아래와 같다.
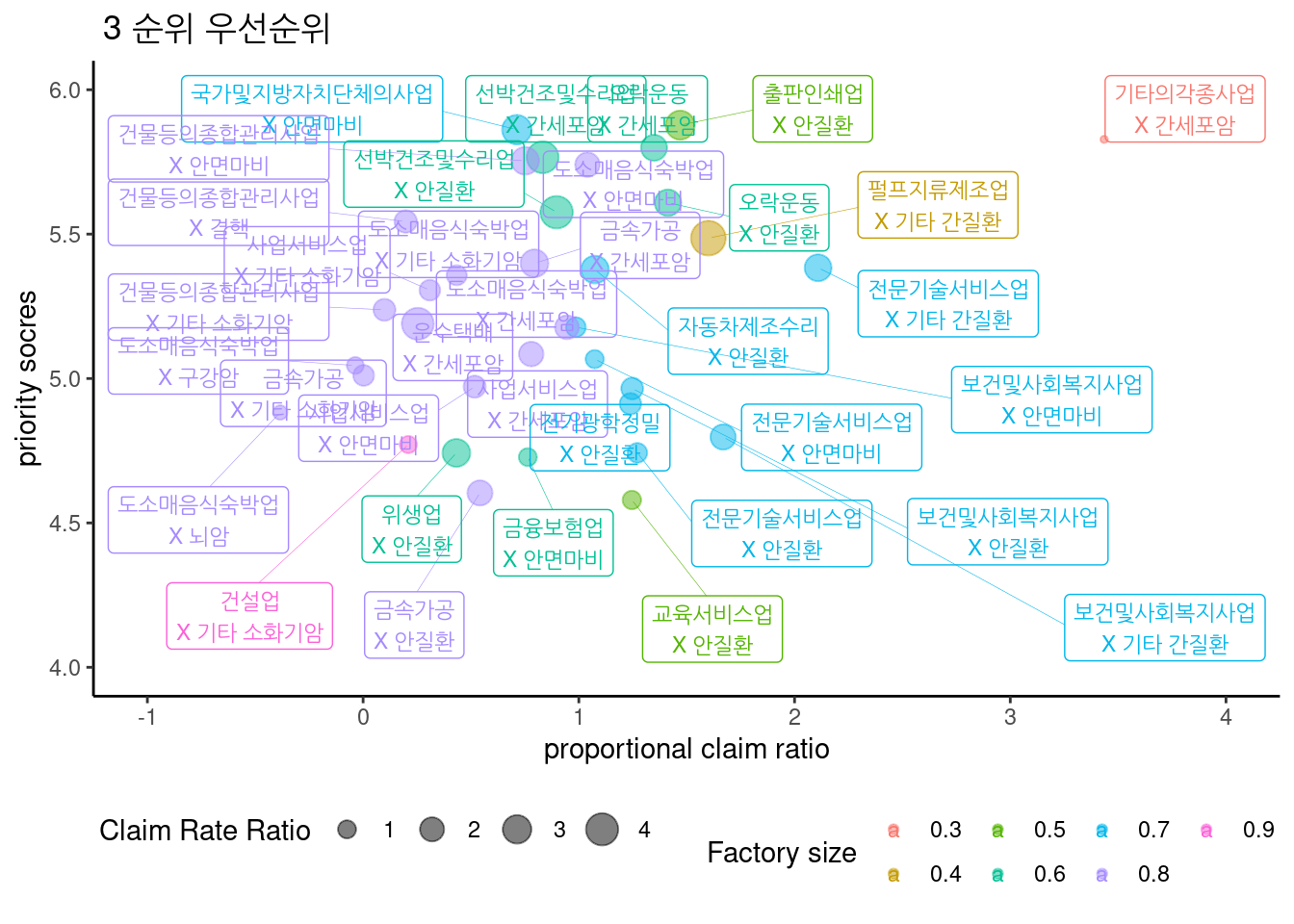 표는 아래와 같다.
표는 아래와 같다.
3.2.19.4 score 1 군 우선순위
최종 score에 따른 4군 우선 순위는 아래와 같다.
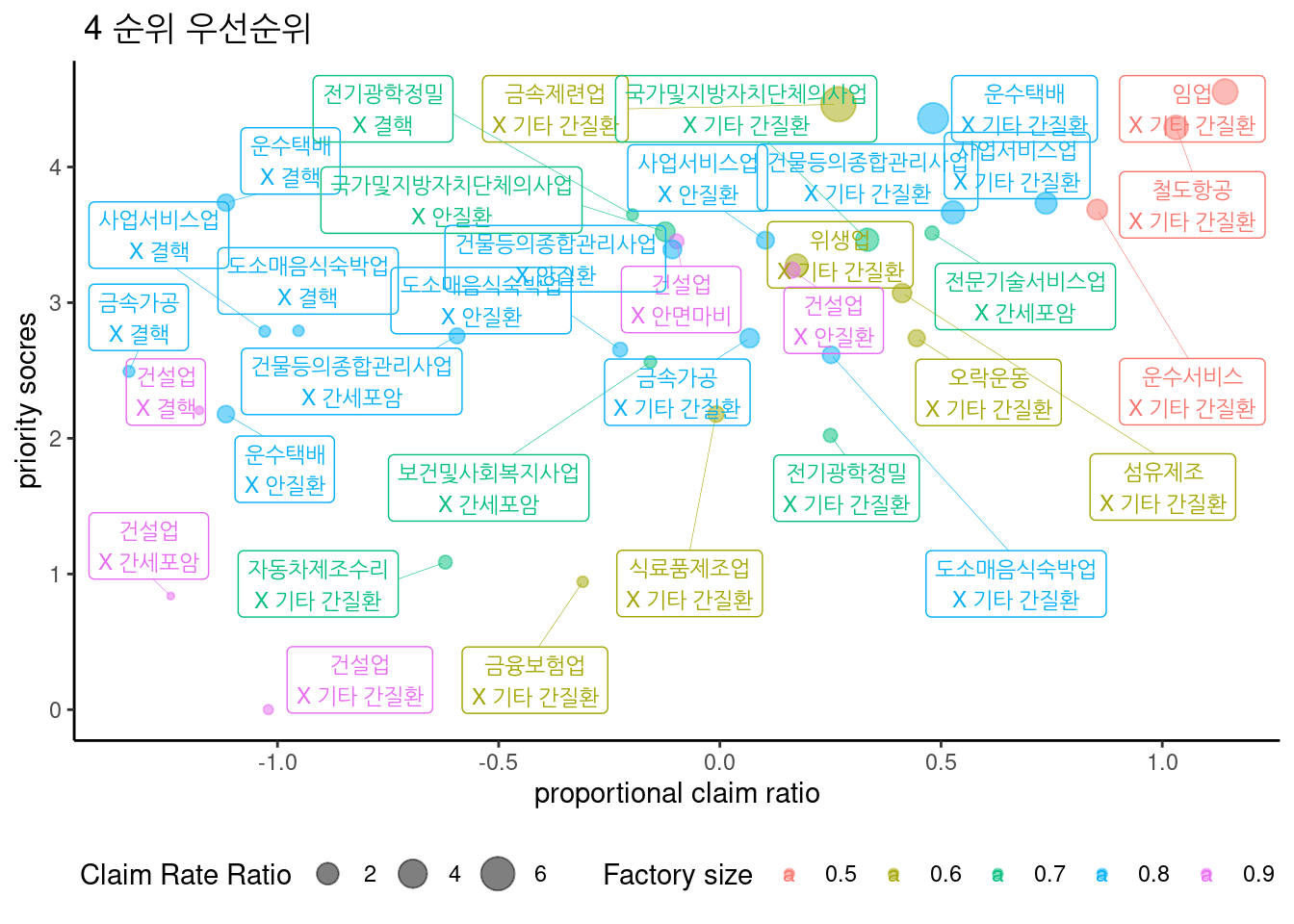
표는 아래와 같다.
3.2.20 업종 대분류별 우선순위
업종별 관찰은 아래와 같다.
dat %>%
select('main_industry' = ind_main, industry, disease, scores) %>%
datatable() %>% formatRound('scores', digits = 2)3.2.20.1 건설업 중 우선순위
건설업 중 우선 순위는 다음과 같다.
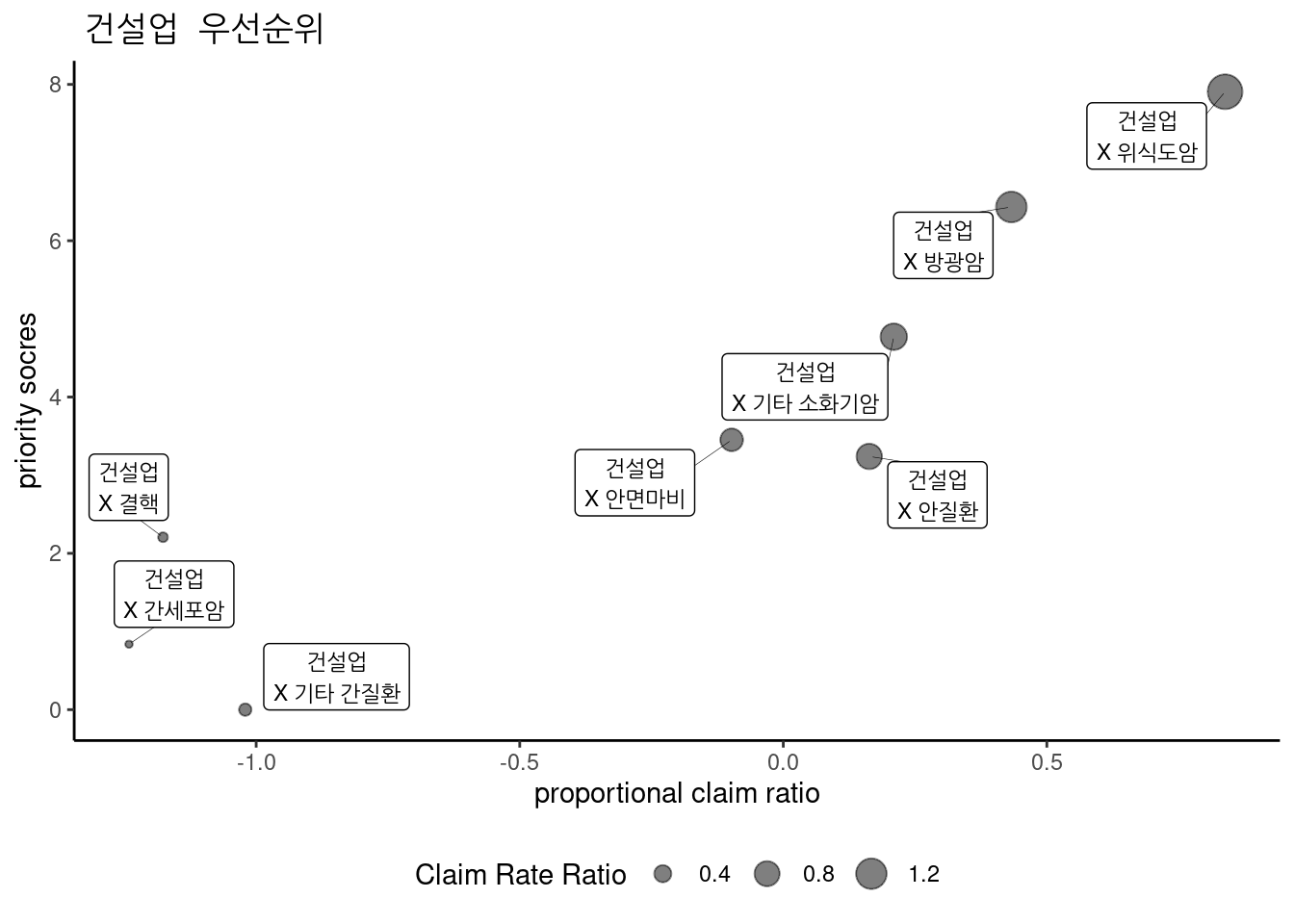
3.2.20.2 금융보험업 중 우선순위
금융보험업 중 우선 순위는 다음과 같다.
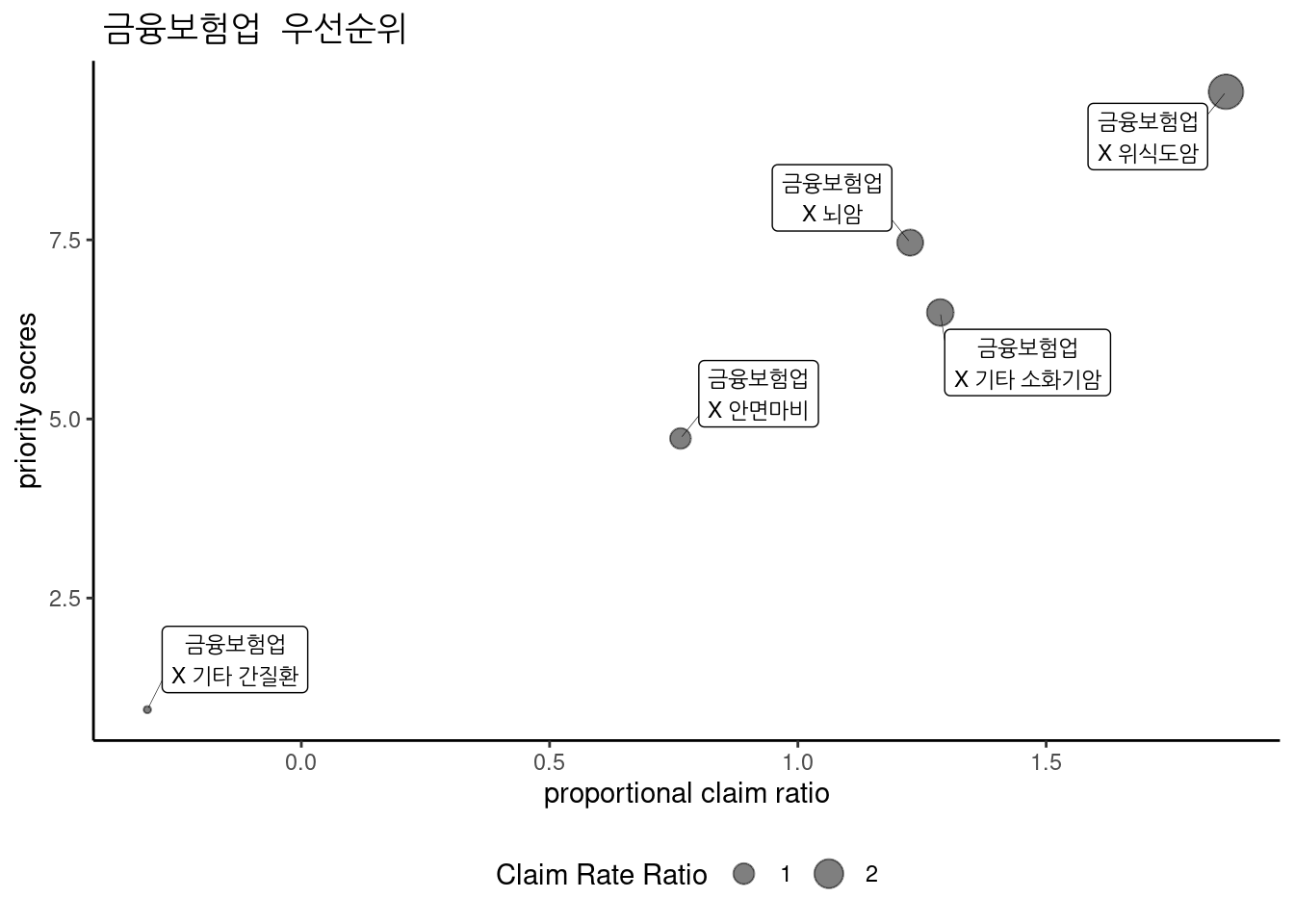
3.2.20.3 기타의사업 중 우선순위
기타의사업 중 우선 순위는 다음과 같다.

3.2.20.4 농림어업 중 우선순위
농림어업 중 우선 순위는 다음과 같다.
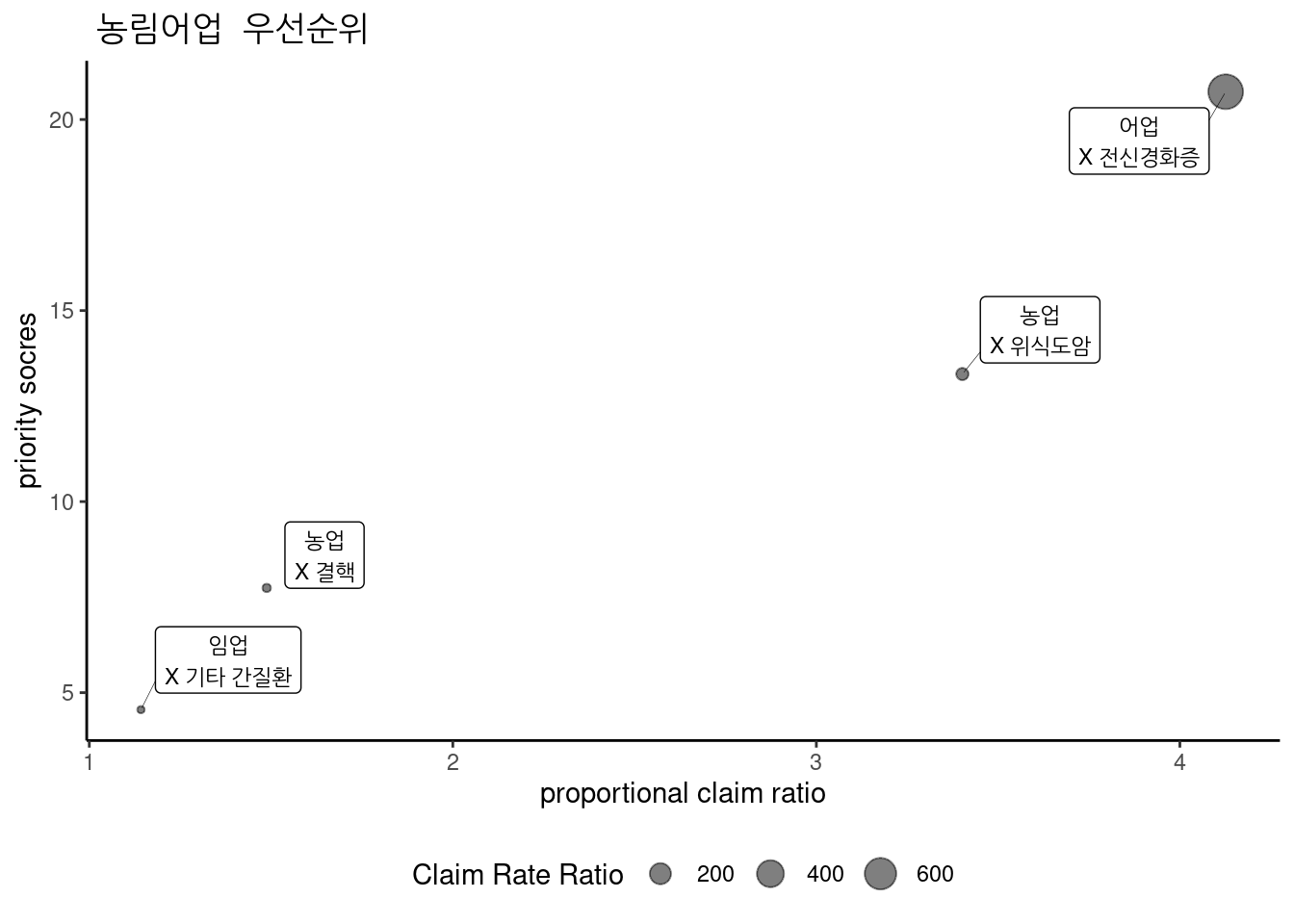
3.2.20.5 운수창고통신업 중 우선순위
운수창고통신업 중 우선 순위는 다음과 같다.
![]()
3.2.20.6 전기가스수도업 중 우선순위
전기가스수도업 중 우선 순위는 다음과 같다.
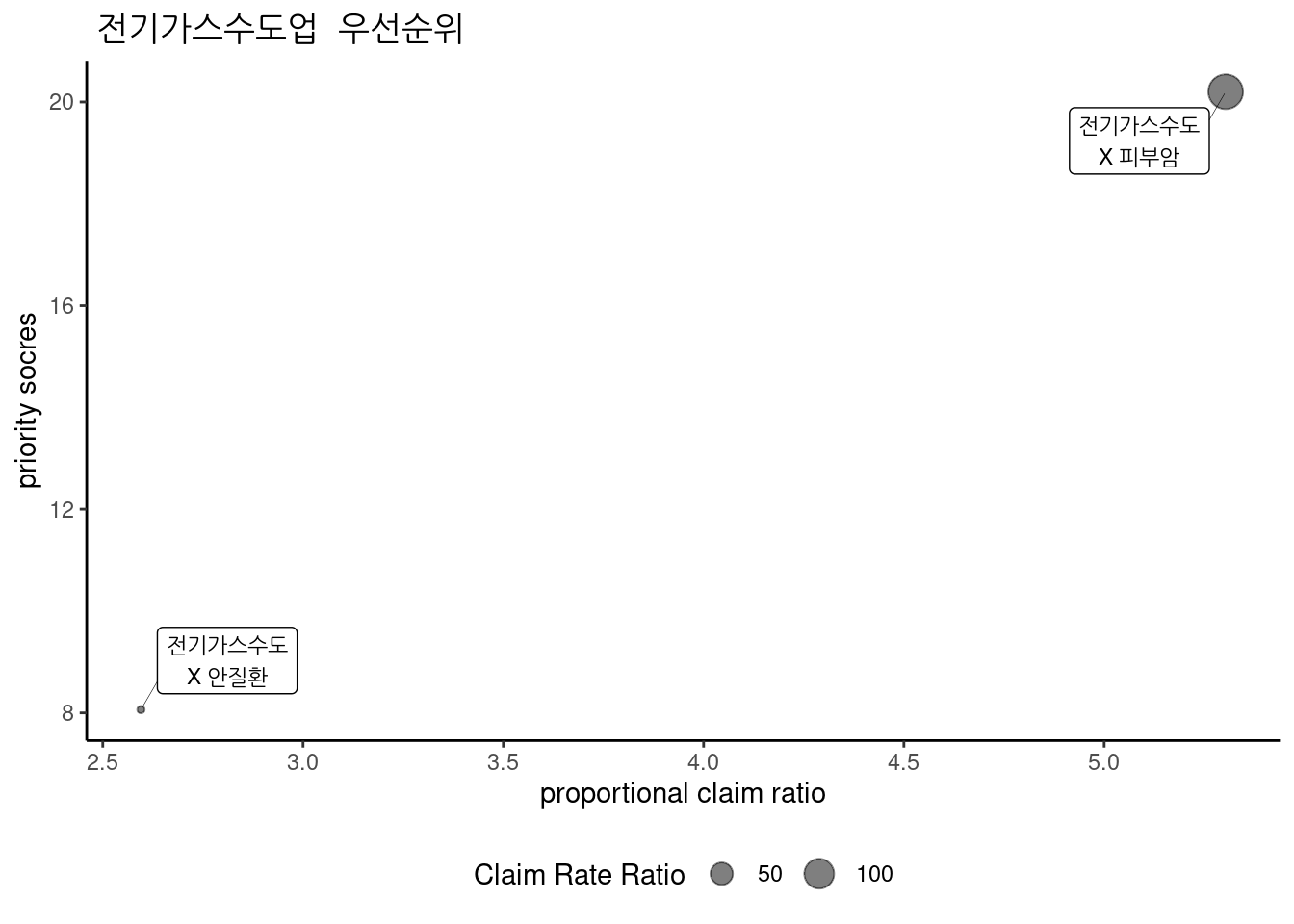
3.2.20.7 제조업 중 우선순위
제조업 중 우선 순위는 다음과 같다.