Chapter 13 Data Wrangling- Text value Handling
데이터 시각화 및 데이터 표준화를 위해서 반드시 수행되는 과정입니다. 데이터를 어떻게 사용할 것인가와 최종 사용 양상을 고려해서 이에 맞도로 데이터를 수정하는 과정입니다. 이에 자주 사용하는 방법은 gather, spread, seprate, unite, unique등이 이 있습니다 이에 대한 실습을 수행하겠습니다. 제가 어떠한 일을 한때 50%는 위의 pivot_longer, pivot_wider, seprate, unique와 str_()를 사용하게 됩니다. 추가적 내용은 Garrett Grolemund, Hadley Wickham의 R for Data Science예제와 실습과제를 이용하여 살펴 보시기 바랍니다 . stringr을 이용해서 문자 변수를 핸들링하게 되는데 이때 알야될 부분은 Regular Expressions이고 이는 아래 cheat sheet을 살펴보면서 응용하시면 됩니다. 참고로 Rstudio에서 여러 cheat sheet을 제공하는데 (https://rstudio.com/resources/cheatsheets/) 필요에 따라 사용하시기 바랍니다. 우선 Stringr Cheat Sheet는 https://github.com/rstudio/cheatsheets/raw/master/strings.pdf 여기서 다운로드받으세요.
13.2 문제 제기
아래와 같은 파일을 불러와 봅시다. 자료는 google classroom에 기타공지 Data Wrangling example에 있습니다.
library(tidyverse)
library(ggplot2)
library(readxl)
library(DT)url = "https://dspubs.org/webapps/forum/open_data/exp00.xlsx"
download.file(url, "data/exp00.xlsx")
exp1 <- read_xlsx('data/exp00.xlsx')아래 데이터를 살펴보면 exposure 변수에 값들이 있고, 이 값들은 ,를 이용하여 구분되고 있습니다. 우리가 자주 사용하는 데이터를 입력하는데 있어서 여러 에러를 없애기 위해 상기 방법을 사용하고는 합니다. 그런데 막상 분석을 수행하여 망간에 노출된 사람이 몇명인가를 어떻게 알수 있을까요? 가장 쉬운 방법은 str_detect()를 사용하는 것입니다. 그러나 소음은, 톨루엔은, 분진은, 염화비닐은 이렇게 늘어나는 경우에는 어떻게 하는 것이 좋을 까요 그것은 long form 또는 wide form으로 데이터를 만드는 것입니다.
head(exp1$exposure)## [1] "망간및그무기화합물함유제제,산화아연(흄)함유제제,크롬과그무기화합물(수용성 6가크롬),소음,용접흄"
## [2] "망간및그무기화합물함유제제,산화아연(흄)함유제제,크롬과그무기화합물(수용성 6가크롬),소음,용접흄"
## [3] "일반검진,망간및그무기화합물함유제제,산화아연(흄)함유제제,산화철분진과흄함유제제,크롬과그무기화합물(수용성 6가크롬),소음,용접흄"
## [4] "일반검진,망간및그무기화합물함유제제,산화아연(흄)함유제제,산화철분진과흄함유제제,크롬과그무기화합물(수용성 6가크롬),소음,용접흄"
## [5] "일반검진"
## [6] "일반검진,메틸알코올,포름알데히드,방사선"우선 한 변수 안에 여러 변수값(value)가 ,로 구분되어 있는 것을 여러 변수 또는 여러 독립된 변수값으로 변형해 보겠습니다.
13.3 split
split를 사용하여 ,로 이루어진 변수를 나누어 보겠습니다. split는 문자를 다룰 때 가장 많이 사용하는 명령문 중 하나입니다. 이번 시간에는 tidyverse 패키지와의 통일을 위해 str_split을 사용하겠습니다. fruits에 사과와 딸기와 오렌지라는 문장이 있고, 이때 와를 기준으로 단어를 나누어 보겠습니다.
fruits <- c(
"사과와 딸기와 오렌지 "
)
split_sentence <- str_split(fruits, "와" )
split_sentence## [[1]]
## [1] "사과" " 딸기" " 오렌지 "같은 방법으로 위 exposure자료를 ,를 기준으로 나누어 보겠습니다. 아래에서 , 를 기준으로 나누었을때 첫번째 항이 일반검진과 망간(분진및 그화합물)로 나누어 진것을 볼 수 있습니다.
str_split(exp1$exposure, ",", simplify = TRUE) %>%
head()## [,1] [,2]
## [1,] "망간및그무기화합물함유제제" "산화아연(흄)함유제제"
## [2,] "망간및그무기화합물함유제제" "산화아연(흄)함유제제"
## [3,] "일반검진" "망간및그무기화합물함유제제"
## [4,] "일반검진" "망간및그무기화합물함유제제"
## [5,] "일반검진" ""
## [6,] "일반검진" "메틸알코올"
## [,3] [,4]
## [1,] "크롬과그무기화합물(수용성 6가크롬)" "소음"
## [2,] "크롬과그무기화합물(수용성 6가크롬)" "소음"
## [3,] "산화아연(흄)함유제제" "산화철분진과흄함유제제"
## [4,] "산화아연(흄)함유제제" "산화철분진과흄함유제제"
## [5,] "" ""
## [6,] "포름알데히드" "방사선"
## [,5] [,6] [,7] [,8] [,9] [,10] [,11]
## [1,] "용접흄" "" "" "" "" "" ""
## [2,] "용접흄" "" "" "" "" "" ""
## [3,] "크롬과그무기화합물(수용성 6가크롬)" "소음" "용접흄" "" "" "" ""
## [4,] "크롬과그무기화합물(수용성 6가크롬)" "소음" "용접흄" "" "" "" ""
## [5,] "" "" "" "" "" "" ""
## [6,] "" "" "" "" "" "" ""
## [,12] [,13] [,14]
## [1,] "" "" ""
## [2,] "" "" ""
## [3,] "" "" ""
## [4,] "" "" ""
## [5,] "" "" ""
## [6,] "" "" ""다만 몇가지 NA가 보이고 있습니다. NA는 문자이므로 ““를 통해 빈칸으로 만들어 주겠습니다.
exp.m <-str_split(exp1$exposure, ",", simplify = TRUE) %>%
as.data.frame() %>%
na_if(., "")
datatable(head(exp.m[, 1:5]))이렇게 만들어 진 파을 처음 파일과 합치도록 하겠습니다.
exp2 <- cbind(exp1, exp.m)
exp3 <- exp2 %>%
select(-exposure)
datatable(head(exp3[, 1:6]) )13.4 gather (pivot_longer)
visiting occurrence,data, id에 대해서 long form 데이터를 만들어 분석하기 쉽게 하도록 하겠습니다. 무언가 좀더 자주 보는 모양의 데이터가 되었습니다.
exp4 <- exp3 %>%
pivot_longer(!c(vo, sdate, id),
names_to = 'Vs', values_to = 'exposure')
head(exp4)## # A tibble: 6 × 5
## vo sdate id Vs exposure
## <dbl> <chr> <dbl> <chr> <chr>
## 1 48064 2008-03-21 1 V1 망간및그무기화합물함유제제
## 2 48064 2008-03-21 1 V2 산화아연(흄)함유제제
## 3 48064 2008-03-21 1 V3 크롬과그무기화합물(수용성 6가크롬)
## 4 48064 2008-03-21 1 V4 소음
## 5 48064 2008-03-21 1 V5 용접흄
## 6 48064 2008-03-21 1 V6 <NA>이때 발생된 NA는 빈칸을 억지로 가져오면서 생긴 것이기 때문에 필요가 없고, Vs 또한 필요한 부분이 아닙니다. 따라서 na.omit()을 이용하여 지우도록 하겠습니다.
exp4 <- exp3 %>%
pivot_longer(!c(vo,sdate,id),
names_to = 'Vs', values_to = 'exposure') %>%
select(-Vs) %>%
na.omit()
head(exp4)## # A tibble: 6 × 4
## vo sdate id exposure
## <dbl> <chr> <dbl> <chr>
## 1 48064 2008-03-21 1 망간및그무기화합물함유제제
## 2 48064 2008-03-21 1 산화아연(흄)함유제제
## 3 48064 2008-03-21 1 크롬과그무기화합물(수용성 6가크롬)
## 4 48064 2008-03-21 1 소음
## 5 48064 2008-03-21 1 용접흄
## 6 48065 2008-03-21 1 망간및그무기화합물함유제제자 이제 ID가 1인 사람을 관찰해 보겠습니다. 2008년 3월과 2008년 7월에 용접흄에 노출되었네요. 좀 보기 편해졌습니다.
exp4 %>%
filter(id ==1)## # A tibble: 24 × 4
## vo sdate id exposure
## <dbl> <chr> <dbl> <chr>
## 1 48064 2008-03-21 1 망간및그무기화합물함유제제
## 2 48064 2008-03-21 1 산화아연(흄)함유제제
## 3 48064 2008-03-21 1 크롬과그무기화합물(수용성 6가크롬)
## 4 48064 2008-03-21 1 소음
## 5 48064 2008-03-21 1 용접흄
## 6 48065 2008-03-21 1 망간및그무기화합물함유제제
## 7 48065 2008-03-21 1 산화아연(흄)함유제제
## 8 48065 2008-03-21 1 크롬과그무기화합물(수용성 6가크롬)
## 9 48065 2008-03-21 1 소음
## 10 48065 2008-03-21 1 용접흄
## # … with 14 more rows13.5 spread (pivot_wider)
이를 wide form으로 만들어 보겠습니다 .
exp5<-exp4 %>%
mutate(values = 1) %>%
pivot_wider(names_from = exposure,
values_from = values,
values_fill = 0)
exp5 %>% head()## # A tibble: 6 × 76
## vo sdate id 망간및그무기화… `산화아연(흄)함…` `크롬과그무기…` 소음
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 48064 2008-03… 1 1 1 1 1
## 2 48065 2008-03… 1 1 1 1 1
## 3 62526 2008-07… 1 1 1 1 1
## 4 62527 2008-07… 1 1 1 1 1
## 5 174043 2011-12… 2 0 0 0 0
## 6 306072 2014-12… 3 0 0 0 0
## # … with 69 more variables: 용접흄 <dbl>, 일반검진 <dbl>,
## # 산화철분진과흄함유제제 <dbl>, 메틸알코올 <dbl>, 포름알데히드 <dbl>,
## # 방사선 <dbl>, 기타광물성분진 <dbl>, `니켈(불용성무기화합물)` <dbl>,
## # `주석(금속)` <dbl>, 염화수소 <dbl>, 질산 <dbl>, 황산 <dbl>, 자외선 <dbl>,
## # 기타금속가공유 <dbl>, 생애검진 <dbl>, 아크릴아미드 <dbl>, 엑스선 <dbl>,
## # IPA <dbl>, `염화수소(염산)` <dbl>, 망간및그무기화합물 <dbl>,
## # `메틸에틸케톤(MEK)` <dbl>, 메틸에틸케톤 <dbl>, 톨루엔 <dbl>, …이제 id 1인 근로자의 산화철분진 노출을 관찰해 보겠습니다. id 1인 근로자는 언제 부터 산화철 분진에 노출되었나요? 2008년 7월부터 입니다.
exp5 %>%
select(sdate, id, contains("산화철분진")) %>%
filter(id ==1)## # A tibble: 4 × 3
## sdate id 산화철분진과흄함유제제
## <chr> <dbl> <dbl>
## 1 2008-03-21 1 0
## 2 2008-03-21 1 0
## 3 2008-07-02 1 1
## 4 2008-07-02 1 1저는 데이터 클리닝과 visualization에서는 주로 long form을 데이터 분석에서는 wide form을 사용하고 있습니다.
13.6 stringr
Stringr부분은 강의한다기 보다는 필요한 시기에 cheat를 찾아서 실행해 본다가 맞는 것 같습니다. 다만 여기서 몇가지 실습을 통해 익히고, 앞서 이야기한 cheat를 사용해서 필요한 경우 사용하면 되겠습니다.
13.6.1 분진 노출자 찾기
여러 분진에 노출되는 근로자를 찾아보고 싶습니다. 어떤 데이터에서 찾으면 좋을 까요? 이때 사용할 코드는 str_detect입니다. 구별을 위해 long 과 wide 파일을 만들겠습니다.
long <-exp4
wide <-exp5str_detect는 어떤 변수에 특정 문장이 있으면 TRUE, 아니면 FALSE를 돌려주는 함수 입니다.
fruit <- c('apple', 'banna', 'apple-banna')
str_detect(fruit, 'apple')## [1] TRUE FALSE TRUEstr_detect(fruit, '-')## [1] FALSE FALSE TRUE이를 이용해서 long form에서 찾아 보겠습니다. 10명이 노출되고 있네요.
long %>%
filter(str_detect(exposure, "분진")) %>%
pull(id) %>%
unique() %>%
length()## [1] 10그럼 어떤 분진인지 보겠습니다. 산화철분진, 광물성분진이었네요.
long %>%
filter(str_detect(exposure, "분진")) %>%
pull(exposure) %>%
unique() ## [1] "산화철분진과흄함유제제" "기타광물성분진"13.6.2 특정 문자 변환
찾아보니 기타라는 단어가 있어 혼란이 있네요, 그리고 함유제제와 화합물이라는 것은 필요 없는 단어라고 판단됩니다. 이를 찾아서 지워보겠습니다. str_replace_all을 이용합니다.
long %>%
mutate(exposure2=str_replace_all(exposure, "기타|함유제제|화합물|및그무기", "")) %>%
filter(str_detect(exposure, '납|분진')) %>%
select(exposure, exposure2) %>%
unique()## # A tibble: 5 × 2
## exposure exposure2
## <chr> <chr>
## 1 산화철분진과흄함유제제 산화철분진과흄
## 2 기타광물성분진 광물성분진
## 3 납(연)및그무기화합물함유제제 납(연)
## 4 납(연)및그무기화합물 납(연)
## 5 납.납화합물 납.납13.6.3 과제
R 코드를 작성해 보세요
- “납”의 노출 종류는 몇가지 인가요? 힌트
long %>% filter(str_detect(??, ??)) %>% pull(??) %>% unique()
## [1] "납(연)및그무기화합물함유제제" "납(연)및그무기화합물"
## [3] "납.납화합물"- 납 노출이 일어난 날짜(
sdate)를 찾으세요
## [1] "2007-07-19" "2009-07-13" "2010-07-12" "2011-04-14" "2012-05-07"
## [6] "2013-05-27" "2014-05-26" "2015-04-27"- id 별 소음에 노출된 횟수를 구하고 이를
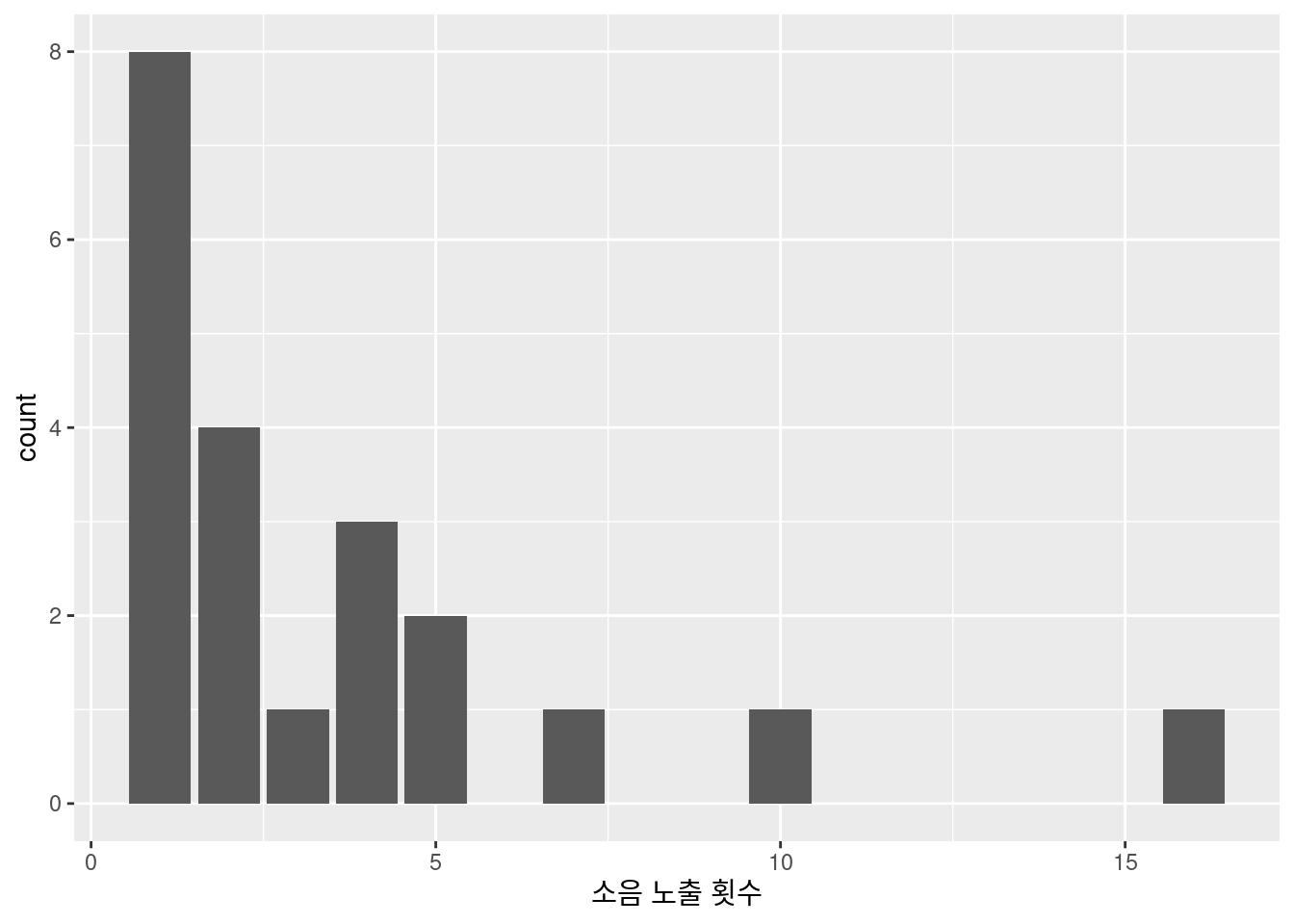
ggplot(aes(x=n)) + geom_bar()를 이용해 그리세요.
- 숫자가 포함된 인자를 찾아보세요, 숫자는
\\d로 표기합니다. d 는 digit이란 뜻이고\\는 그 뒤에 오는 것이 문자가 아니라 약속된 기호라는 뜻입니다. 예를 들면 아래와 같습니다.^가 의미하는 것은 무엇일까요?.$가 뜻하는 것은 무엇일까요. 아래와 같습니다.
fruits <- c('apple2', 'apple', 'a4ple', '4apple', 'b4ple')
str_detect(fruits, '\\d')## [1] TRUE FALSE TRUE TRUE TRUEstr_detect(fruits, '^\\d')## [1] FALSE FALSE FALSE TRUE FALSEstr_detect(fruits, '\\d$')## [1] TRUE FALSE FALSE FALSE FALSEstr_detect(fruits, 'a\\d')## [1] FALSE FALSE TRUE FALSE FALSE- 자 그럼 숫자가 포함된 유해 물질을 찾아 봅시다. 이렇게 결과가 나오게 해보세요!. 아직 1이 있는 사람이 있나요? 숫자만 혼자 있는 경우도 지워보세요.
## # A tibble: 6 × 1
## exposure
## <chr>
## 1 크롬과그무기화합물(수용성 6가크롬)
## 2 야간작업(월평균4회)
## 3 크롬과그무기화합물(불용성 6가크롬)
## 4 2-부톡시에탄올
## 5 3-부타디엔
## 6 크롬(6가)화합물(불용성무기화합물)- 숫자로 시작되는 유해물질을 찾아보세요
## # A tibble: 2 × 1
## exposure
## <chr>
## 1 2-부톡시에탄올
## 2 3-부타디엔