pkgs = c("tidyverse", "htmlTable", "broom", "labelled", "haven", "DT",
"devtools", "lmtest", "ggplot2", "shiny", "shinyWidgets",
"plotly", "httr", "rvest", "jsonlite")
for (pkg in pkgs){
if(!require(pkg, character.only = T)) install.packages(pkg)
library(pkg, character.only = T)
}
if(!require("tabf")) install_github("jinhaslab/tabf")
library(tabf)19 생성형 AI 사용
19.1 기계는 어떻게 학습할까?
기계는 어떻게 학습할까?
- 기계가 학습을 할 때,
- 개념적으로 문제가 있고 이에 맞는 답이 있는 경우,
- 문제는 나열되어 있고 비슷한 문제끼리 묶어야 하는 경우,
- 해보고 뭐가 문제인지 뭐가 답인지 경험해보고 보상받는 경우로
구분해 볼 수 있습니다. 각각 지도학습, 비지도학습, 강화학습이라고 합니다.
19.2 ChatGPT 의 간단 소개
- 대형언어모델이다. (GPT는 비지도학습, 미세조정)
- 문장에서 다음에 오는 단어를 예측하는 방식
- 많이 읽어서 확률적 분포를 예측한다. → 구조 이용
- 인간피드백을 이용한 강화 학습이다. (강화학습)
- 인간의 피드백을 바탕으로 보상이나 벌점을 주고, 높은 점수를 받는 쪽으로 유도하는 방법
- 이후 반복적 미세 조정을 통해 성능을 향상시킴
19.3 생성된 방식대로 사용하기
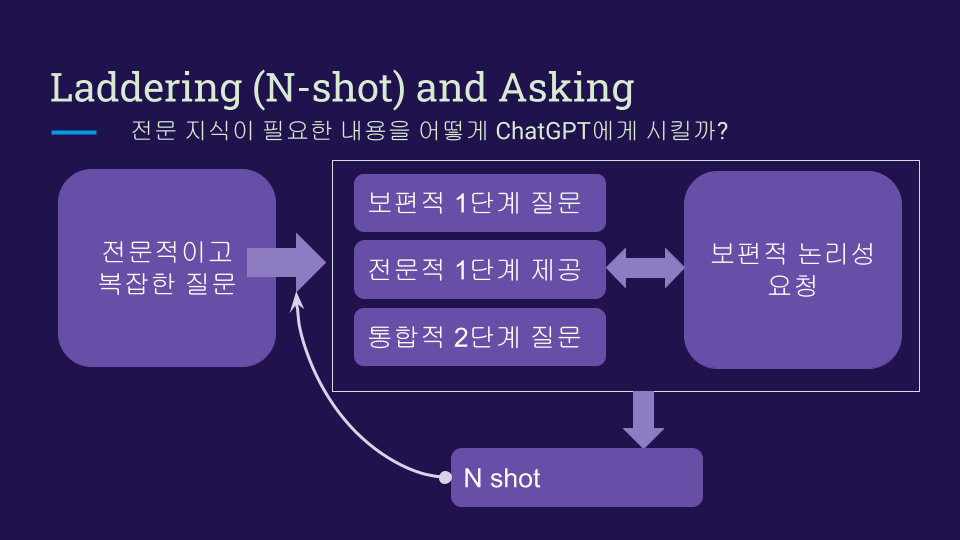
ChatGPT에게 질문할 때 사용할 수 있는 ‘Laddering (N-shot)’과 ’Asking’ 접근 방식에 대한 순서도가 나타나 있습니다. 그림을 통해 정보를 얻거나 대화를 진행할 때 단계별로 어떻게 접근하는 것이 효과적인지 생각해 보세요.
위 그림은 다음과 같은 단계를 포함하고 있습니다:
- 질문 정의 및 분명한 질문 설정: 대화의 시작점에서, 명확하고 구체적인 질문을 통해 대화를 시작합니다.
- 분명한 1단계 질문: 첫 번째 단계에서는 주제에 대한 기본적인 정보를 얻기 위해 직접적인 질문을 합니다.
- 질문 군 1단계 제공: 초기 질문에 대한 답변을 바탕으로, 보다 구체적인 세부 사항을 파악하기 위한 추가 질문을 합니다.
- 통합적 2단계 질문: 이 단계에서는 앞선 답변들을 통합하여 깊이 있는 이해를 위한 질문을 합니다.
- 보다 깊은 논리성 요청: 답변에서 더 깊이 있는 논리나 이유를 요청함으로써, 사물의 본질이나 근본적인 원인을 탐구합니다.
- N shot: 위의 단계를 여러 번 반복하여 주제에 대한 포괄적인 이해를 구축합니다.
- 이 과정은 깊이 있는 대화를 위한 좋은 가이드라인을 제공하며, 사용자가 ChatGPT와의 상호작용을 최대화하기 위한 전략적인 질문 방식을 개발하는 데 도움을 줄 수 있습니다.
강의 자료를 통해 이야기 하겠습니다.
19.4 생성형 AI와 이야기 하기
아래 코드를 통해 기존에 논의했던 logistic regression 표를 생성해 봅니다.
url1 <- "https://raw.githubusercontent.com/jinhaslab/opendata/main/kwcs/myoutput.rds"
download.file(url1, "data/myoutput.rds")
#myoutput = readRDS("results/myoutput.rds")
myoutput = readRDS("data/myoutput.rds")
mytab1 = myoutput
mytab1| Table. OR(95%CI) for sleepgp of 1.sleep disturbance | ||
|---|---|---|
| Variables | Values | Model.I |
| int | 0.Rarely with 0.non short return | 1.00 (reference) |
| 1.≥Sometimes with 0.non short return | 1.53 (1.36-1.73) | |
| 0.Rarely with 1.short return | 1.97 (1.31-2.97) | |
| 1.≥Sometimes with 1.short return | 6.64 (5.46-8.06) | |
| edugp | 0.university or more | 1.00 (reference) |
| 1.high school | 1.02 (0.91-1.14) | |
| 2.middle school or below | 1.68 (1.39-2.04) | |
| AGE | 1.01 (1.01-1.02) | |
이 표를 어떻게 chatGPT에게 설명해 달라고 할 수 있을까요?
우선 api_key가 있어야 합니다. 이걸 통해서 chatGPT와 소통할 것입니다.
api_key_report = "your key"우선 보내고 싶은 table을 R에서 사용할 수 있는 표로 만듭니다.
mytab1 %>% read_html() %>% html_nodes("table") %>% html_table[[1]]
# A tibble: 10 × 3
X1 X2 X3
<chr> <chr> <chr>
1 "Table. OR(95%CI) for sleepgp of 1.sleep disturbance" "Table. OR(95%CI… Tabl…
2 "Variables" "Values" Mode…
3 "int" "0.Rarely with 0… 1.00…
4 "" "1.≥Sometimes w… 1.53…
5 "" "0.Rarely with 1… 1.97…
6 "" "1.≥Sometimes w… 6.64…
7 "edugp" "0.university or… 1.00…
8 "" "1.high school" 1.02…
9 "" "2.middle school… 1.68…
10 "AGE" "" 1.01…mytab1 %>% read_html() %>% html_nodes(“table”) %>% html_table: mytab1 변수에 저장된 데이터를 HTML 테이블로 읽고 변환합니다. 이 코드는 mytab1이 HTML 형식의 데이터를 포함하고 있다고 가정합니다. read_html, html_nodes, html_table 함수들은 각각 HTML 데이터를 읽고, HTML 내의 테이블 요소를 찾고, 이를 R에서 사용할 수 있는 테이블 형식으로 변환하는 데 사용됩니다.
ai_models="gpt-3.5-turbo"
tm=0.1
cm_tmp=c("Please summarize the my result provided below,write it like a report document,
and express it in sentences as public health specilist.")
addinfor = c("wwa1gp is worry about work after finished work")ai_models=“gpt-3.5-turbo”: ai_models 변수에 “gpt-3.5-turbo”라는 문자열을 할당합니다. 이는 특정 인공지능 모델을 지칭하는 것으로 보입니다. tm=0.1: tm 변수에 0.1이라는 값을 할당합니다. 이 값의 정확한 용도는 코드에서 명시되어 있지 않지만, 일반적으로 시간이나 임계값 등을 나타내는 데 사용됩니다. cm_tmp: 사용자가 요청한 내용을 포함하는 문자열 배열을 정의합니다. 여기에는 결과를 공중보건 전문가처럼 보고서 형식으로 요약하라는 지시가 포함되어 있습니다. addinfor: 추가 정보를 제공하는 addinfor 변수가 정의되어 있으며, 이는 “wwa1gp is worry about work after finished work”라는 문자열을 포함합니다.
mytable1 = mytab1 %>%
read_html() %>%
html_nodes("tr") %>%
html_text(trim=TRUE)
mytable1 [1] "Table. OR(95%CI) for sleepgp of 1.sleep disturbance"
[2] "Variables\nValues\nModel.I"
[3] "int\n0.Rarely with 0.non short return\n1.00 (reference)"
[4] "1.≥Sometimes with 0.non short return\n1.53 (1.36-1.73)"
[5] "0.Rarely with 1.short return\n1.97 (1.31-2.97)"
[6] "1.≥Sometimes with 1.short return\n6.64 (5.46-8.06)"
[7] "edugp\n0.university or more\n1.00 (reference)"
[8] "1.high school\n1.02 (0.91-1.14)"
[9] "2.middle school or below\n1.68 (1.39-2.04)"
[10] "AGE\n\n1.01 (1.01-1.02)" - HTML 데이터 처리:
- read_html(): mytab1 변수에서 HTML 데이터를 읽습니다. read_html 함수는 rvest 패키지의 일부로, HTML 문서를 R의 세션으로 가져오는 데 사용됩니다.
- html_nodes(“tr”): 읽어들인 HTML 문서에서 모든 행( 태그)을 찾습니다. html_nodes 함수는 지정된 CSS 선택자에 해당하는 HTML 노드들을 추출하는 데 사용됩니다.
- html_text(trim=TRUE): 각 행의 텍스트 내용을 추출합니다. trim=TRUE 옵션은 텍스트의 앞뒤 공백을 제거합니다.
- 결과 저장 및 출력:
- mytable1: 위의 파이프라인을 통해 처리된 데이터는 mytable1이라는 새로운 변수에 저장됩니다.
myquestion = sprintf("%s, consider my special request of %s. {result} is {%s}",
cm_tmp,
addinfor,
paste(mytable1, collapse=" "))
myquestion %>% htmlTable()| Please summarize the my result provided below,write it like a report document, and express it in sentences as public health specilist., consider my special request of wwa1gp is worry about work after finished work. {result} is {Table. OR(95%CI) for sleepgp of 1.sleep disturbance Variables Values Model.I int 0.Rarely with 0.non short return 1.00 (reference) 1.≥Sometimes with 0.non short return 1.53 (1.36-1.73) 0.Rarely with 1.short return 1.97 (1.31-2.97) 1.≥Sometimes with 1.short return 6.64 (5.46-8.06) edugp 0.university or more 1.00 (reference) 1.high school 1.02 (0.91-1.14) 2.middle school or below 1.68 (1.39-2.04) AGE 1.01 (1.01-1.02)} |
response <- POST(
url = "https://api.openai.com/v1/chat/completions",
add_headers(Authorization = paste("Bearer", api_key_report)),
content_type_json(),
encode = "json",
body = list(
model = ai_models,
temperature = 0.1,
messages = list(list(role = "user", content = myquestion))
)
)
content <- content(response, as = "text")
parsed_content <- fromJSON(content)
parsed_content$choices[2]$message$content- API 요청 설정 (POST 함수 사용):
- url = “https://api.openai.com/v1/chat/completions”: OpenAI의 채팅 API 엔드포인트로 요청을 보냅니다.
- add_headers(Authorization = paste(“Bearer”, api_key_report)): API 사용을 인증하기 위해 ‘Bearer’ 토큰을 포함한 헤더를 추가합니다. 여기서 api_key_report는 API 키를 가리킵니다.
- content_type_json(): 요청의 내용이 JSON 형식임을 명시합니다.
- encode = “json”: 요청 본문을 JSON으로 인코딩합니다.
- 요청 본문 설정 (body):
- model = ai_models: 사용할 모델을 지정합니다. 여기서 ai_models 변수는 앞서 설정된 모델 이름(예: “gpt-3.5-turbo”)을 포함합니다.
- temperature = 0.1: 응답의 창의성을 결정하는 온도 값을 설정합니다. 낮은 값은 더 일관되고 예측 가능한 응답을 생성합니다.
- messages = list(list(role = “user”, content = myquestion)): 사용자의 질문을 포함하는 메시지 리스트를 설정합니다. 여기서 myquestion은 사용자의 질문을 담고 있습니다.
- API 요청 실행 및 응답 처리:
- response: API 요청의 결과를 response 변수에 저장합니다.
- content <- content(response, as = “text”): 응답의 내용을 텍스트 형식으로 추출합니다.
- parsed_content <- fromJSON(content): 텍스트 형식의 응답을 JSON으로 파싱합니다.
- 결과 추출:
- parsed_content\(choices[2]\)message$content: 파싱된 JSON 객체에서 특정 응답 내용을 추출합니다. 이 경로는 JSON 객체 내의 두 번째 ’choice’에 해당하는 메시지의 내용을 가리킵니다.
parsed_content$choices[2]$message$content| [1] The results of the analysis indicate that there is a significant association between sleep disturbance and work-related worries after finishing work. Individuals who reported experiencing sleep disturbance sometimes or more frequently were 1.53 times more likely to worry about work after finishing compared to those who rarely experienced sleep disturbance. Additionally, individuals who reported short returns from work and sometimes or more frequently experienced sleep disturbance were 6.64 times more likely to worry about work after finishing compared to those who rarely experienced sleep disturbance and had non-short returns from work. Furthermore, the results suggest that education level is also associated with sleep disturbance and work-related worries. Individuals with a middle school education or below were 1.68 times more likely to experience sleep disturbance compared to those with a university education or higher. However, there was no significant difference in sleep disturbance and work-related worries between individuals with a high school education and those with a university education or higher. Lastly, the analysis found a small but significant association between age and sleep disturbance. For every one-year increase in age, there was a 1.01 times increase in the likelihood of experiencing sleep disturbance. Overall, these findings highlight the importance of addressing sleep disturbance and work-related worries, particularly among individuals with lower education levels and those who frequently experience short returns from work. Public health interventions should focus on promoting healthy sleep habits and providing support for individuals to manage work-related stress and worries. |
19.5 실용화 예시
shiny와 interractive visualization은 DS project 수업에 있으니 생략하겠습니다.